[파이토치] 파이토치로 CNN 모델을 구현해보자! (GoogleNet편)
안녕하세요! 지난번 포스트인 VGGNet 이후로 오늘은 GoogleNet 관련 포스트입니다. 다음 포스트는 ResNet으로 찾아뵙도록 하겠습니다.
지난번에도 소개드렸다시피 컴퓨터 비전 대회 중에 ILSVRC (Imagenet Large Scale Visual Recognition Challenges)이라는 대회가 있는데, 본 대회는 거대 이미지를 1000개의 서브이미지로 분류하는 것을 목적으로 합니다. 아래 그림은 CNN구조의 대중화를 이끌었던 초창기 모델들로 AlexNet (2012) - VGGNet (2014) - GoogleNet (2014) - ResNet (2015) 순으로 계보를 이어나갔습니다.
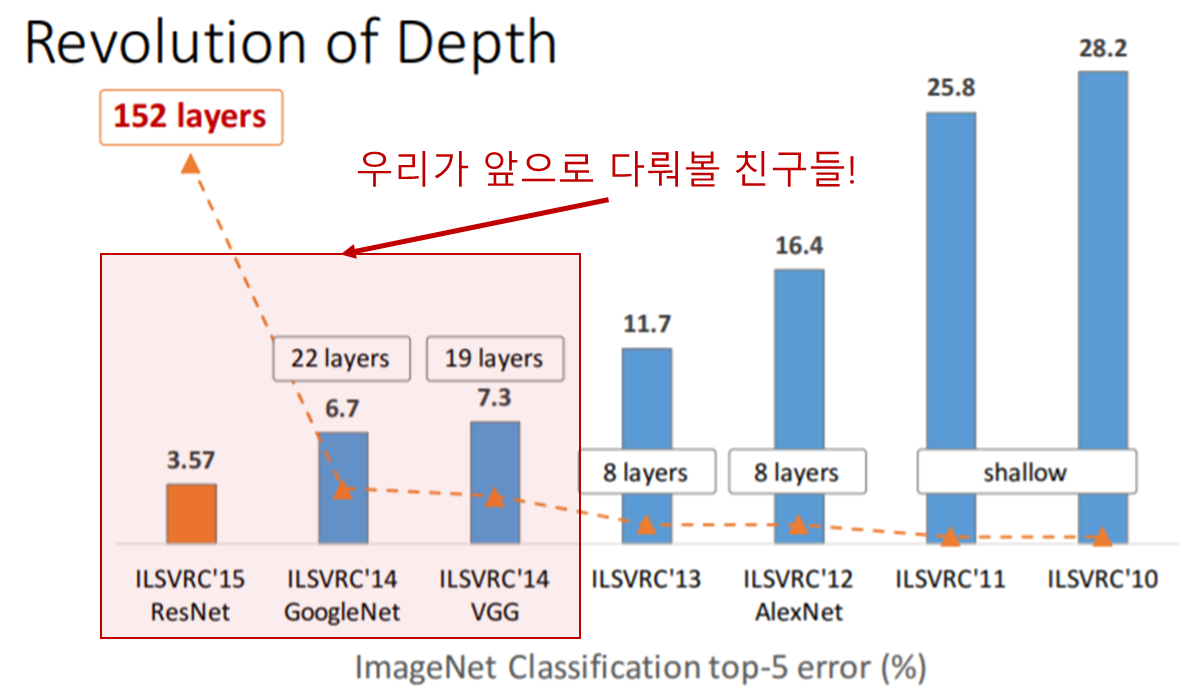
Source : https://icml.cc/2016/tutorials/
위의 그림에서 layers는 CNN layer의 개수(깊이)를 의미하며 직관적인 이해를 위해서 아래처럼 그림을 그려보았습니다.

GoogleNet 개요
소개
GoogleNet이 소개된 논문의 제목은 Going Deeper with Convolutions로, 다음 링크에서 확인해보실 수 있습니다. 링크

일반적으로 모델의 depth와 width가 커지면 parameter가 많아지게 되고, 파라미터 수가 많게되면 모델이 Overfitting될 수 있습니다. GoogleNet은 최대한 파라미터를 줄이면서 네트워크를 깊게 디자인하고자 하였습니다. 모델의 레이어가 깊더라도 연결이 sparse하다면 파라미터 수가 줄어들게 됩니다. 이는 Overfitting 을 방지하는 효과가 있으면서, 연산 자체는 Dense하게 처리하는 것을 목표로 합니다.
GoogleNet은 인셉션(inception) 모듈이라는 블록을 가지고 있어서 인셉션 네트워크라고도 불립니다. 아래 그림은 GoogleNet의 구조도 입니다. 이전 모델들과 비교하여 훨씬 복잡한 구조로 되어 있는 것을 확인할 수 있습니다.
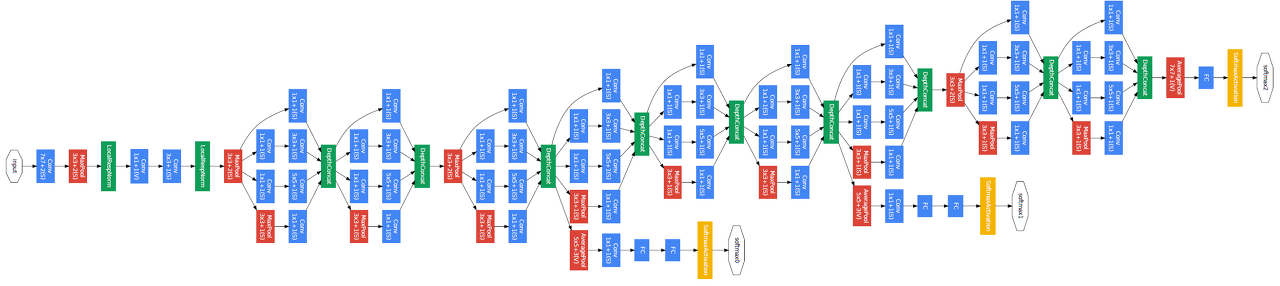
Source : https://arxiv.org/abs/1409.4842
Inception Module
위의 구조도를 살펴보면 뭔가 여러갈래로 갈라졌다가 모이는 형태를 하고 있는 것을 확인할 수 있습니다. 이렇한 모듈(블록)을 인셉션(Inception) 모듈이라고 하며 이는 아래 그림과 같습니다.
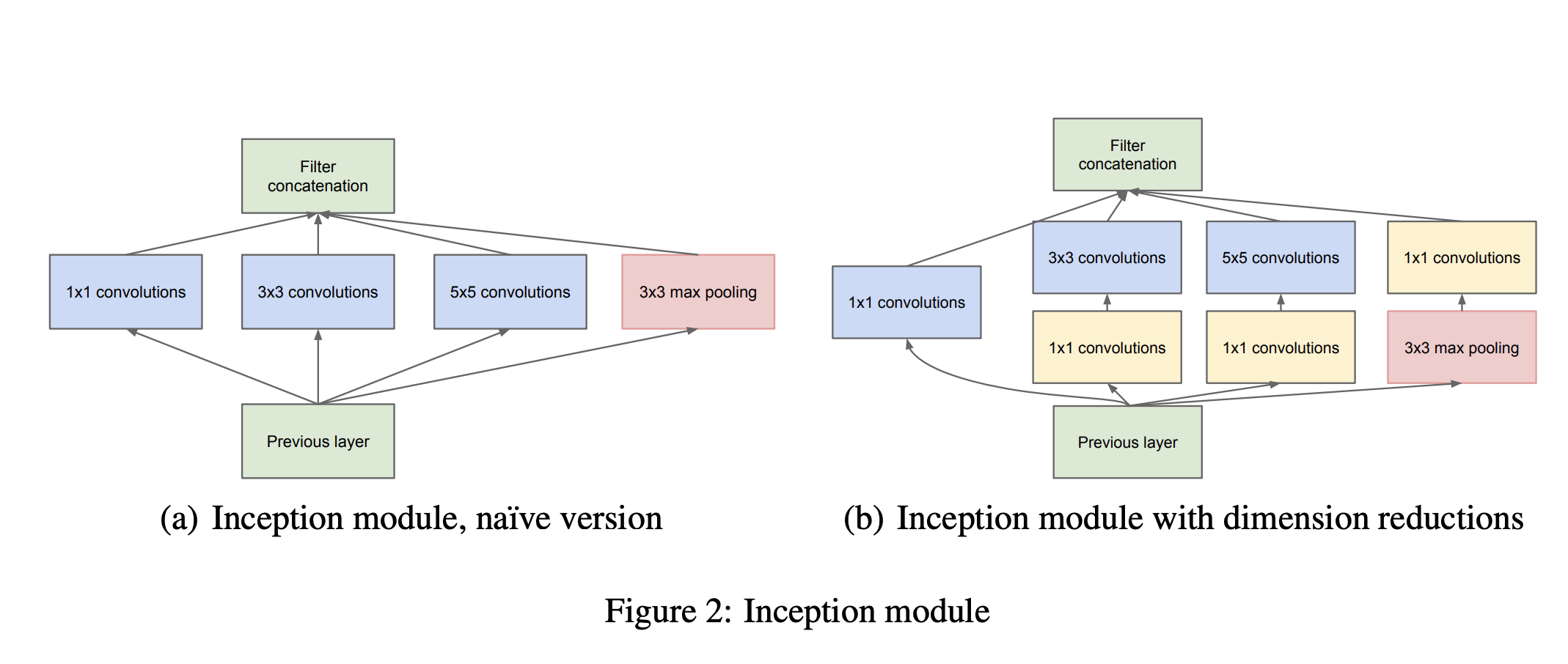
인셉션 모듈은 Feature를 효율적으로 추출하기 위해 1x1, 3x3, 5x5 convolution 연산을 각각 수행하게 됩니다. 가장 먼저 좌측에 있는 (a) Naive Inception에 대하여 살펴보도록 하겠습니다.
(a) Naive Inception
Naive Inception은 이전 단계의 Activation Map에 대하여 1x1, 3x3, 5x5합성곱 연산을 수행한 뒤 각각의 결과를 concatenate해주어 다음 단계로 넘어갑니다. 이는 앙상블의 효과를 갖고 있어 모델이 다양한 관점으로 학습을 할 수 있도록 하는 효과를 가지고 있습니다. 시각화를 통해 어떤 식으로 각각 Naive Inception모듈의 convolution연산이 수행되고 합쳐지는지 아래 도시화해보았습니다.
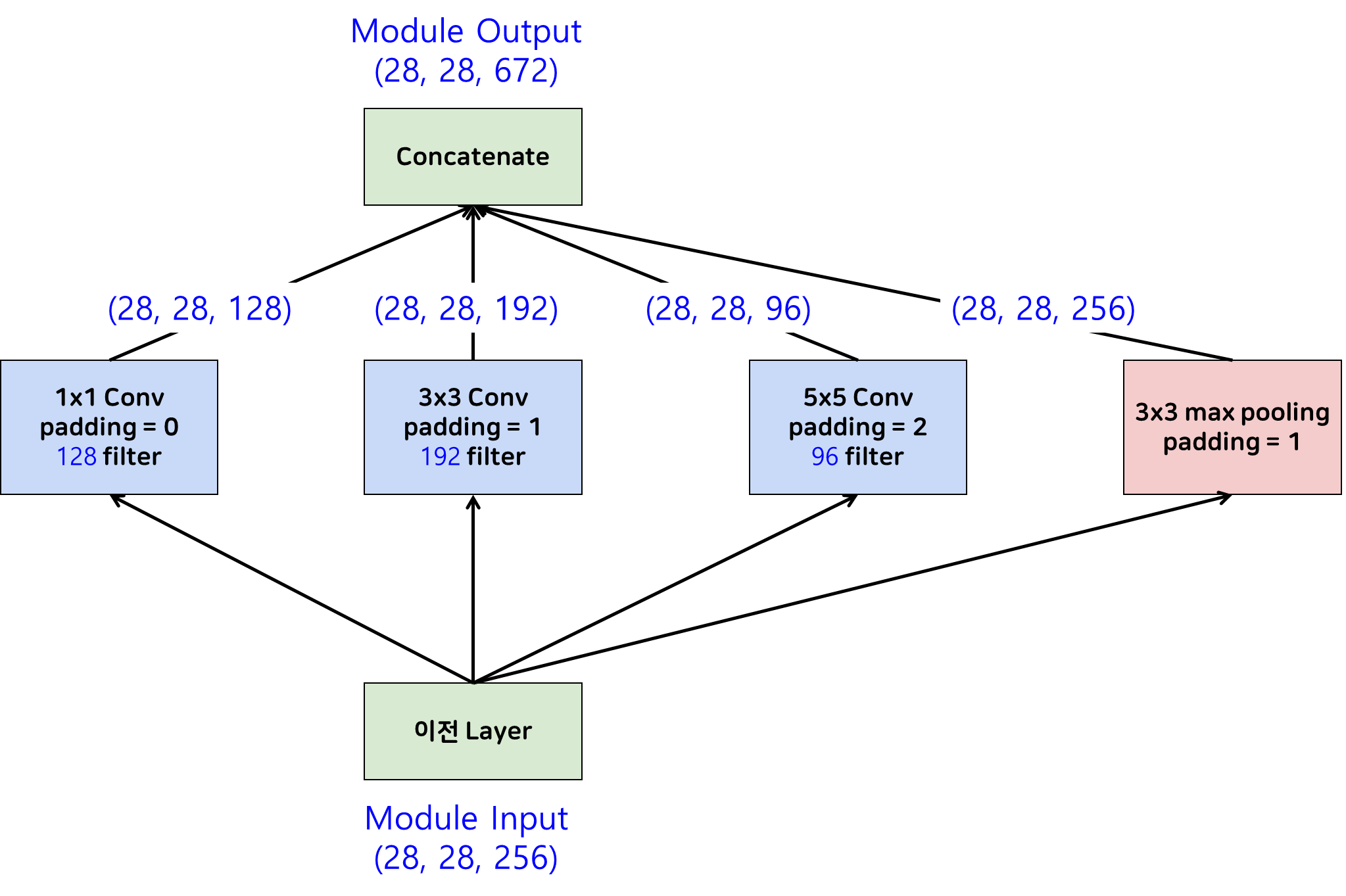
이때 그림을 통해 확인할 수 있는 특징들이 몇가지 존재합니다.
- 1x1 convolution은 별도의 padding이 없습니다.
- 3x3 convolution, 5x5 convolution, 3x3 Pooling 후 concatenate 하기 위해 크기가 같아지도록 적당한 padding을 수행해줍니다.
- 뿐만 아니라 pooling layer의 경우는 channel수가 바뀌지 않기 때문에 층이 깊어질수록 기하급수적으로 channel수가 많아지는 구조가 되게됩니다.
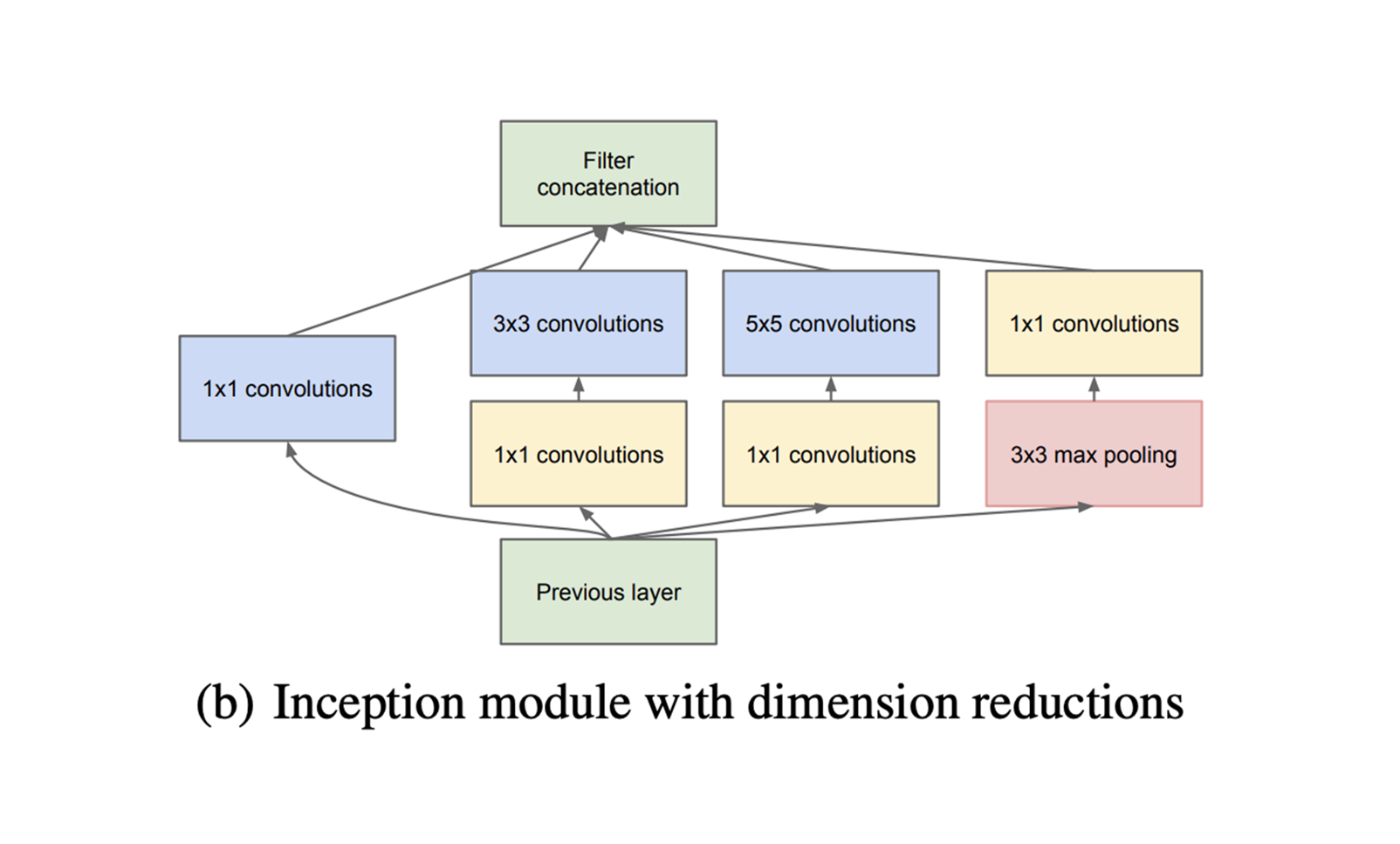
(b) Reduced Dimension Inception
1x1 Convolution
이를 위해 (b) Inception Module wit dimension reduction이 제안되게 되는데요. 이는 1x1 Convolution을 이용하여 dimension reduction을 해줌으로써 computational load를 줄여주게 됩니다. 1x1 Convolution은 직관적으로 1x1 크기를 가지는 Convolution Filter를 사용한 Convolution Layer입니다.
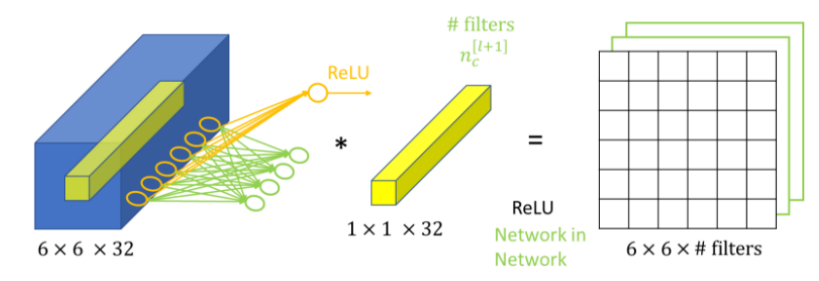
위 그림에서 보실 수 있듯이 input에 1x1 Convolution을 수행하게 되면 feature map의 크기가 동일하게 유지되는 것을 확인할 수 있습니다. 위 그림의 경우 (6x6)이 (6x6)으로 그대로 보존되는 것을 확인할 수 있습니다. 이때 이러한 1x1 convolution 필터를 몇개 사용하는가에 따라 ouput의 출력 채널의 개수를 조절해줄 수 있게됩니다.
GoogleNet은 이러한 1x1 Convolution의 특징을 살려 sparse한 연산을 dense하도록 바꿔주었습니다. 아래 그림을 살펴보시죠.

기존의 (a)에서 5x5 Convolution이 좌측과 같이 112.9M개의 파라미터를 가지고 있다면, (b)에서처럼 1x1 Convolution을 통해 채널 수를 줄여주어 Bottleneck역할을 수행하고, 이를 다시 5x5 Convolution을 통과시켜 같은 output인 14x14x48을 반환해줌에도 불구하고 5.3M개의 파라미터를 갖게하는 것을 볼 수 있습니다.
Global Average Pooling(GAP)
또한, CNN 모델들을 생각해보면 마지막에 softmax 연산을 취하기 전에 아래 그림과 같이 도출된 feature map을 flatten을 통해 쭉 펴서 굉장히 긴 하나의 벡터로 만든 다음, 그 벡터를 Fully Connected Layer에 넣는 방식으로 하나하나 매핑해서 클래스를 분류했습니다.
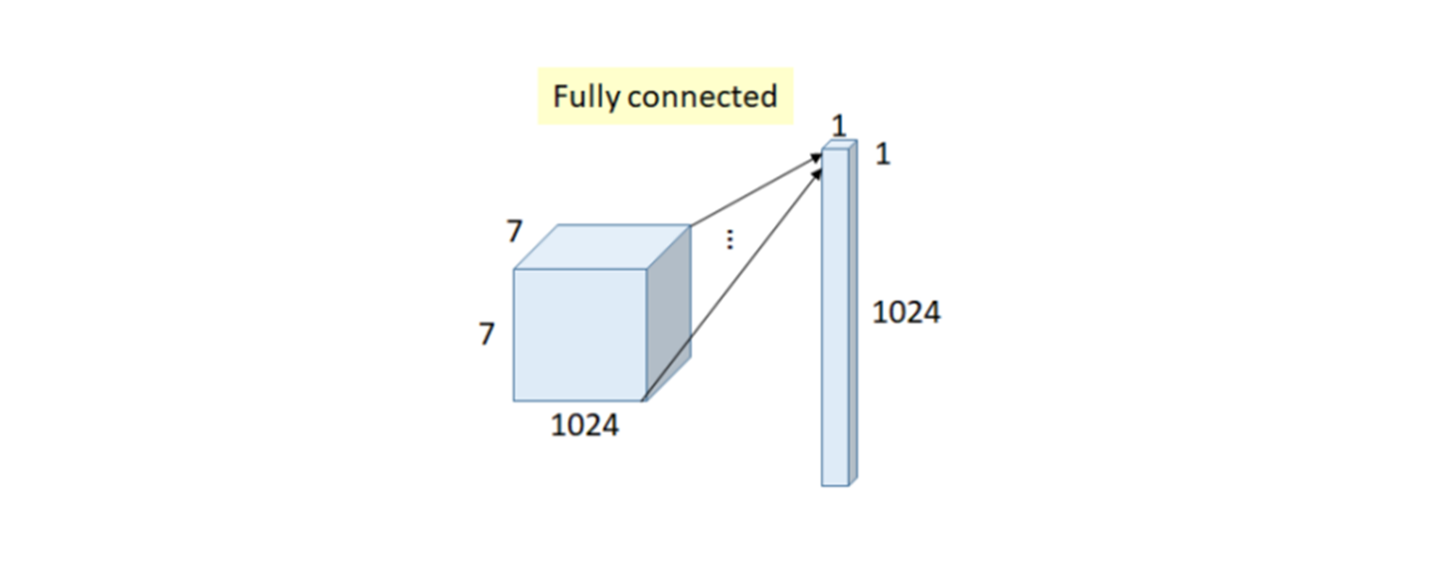
하지만, 이러한 과정은 기존 featuremap의 공간적 정보도 많이 잃어버리는데다가, 굉장히 많은 파라미터가 필요하게 되고, VGGNet의 경우 이 부분이 전체 계산량의 85%를 차지하게 됩니다. 이를 극복하기 위해 제안된 방법이 바로 GAP(Global Average Pooling)로, 아래 그림과 같습니다.
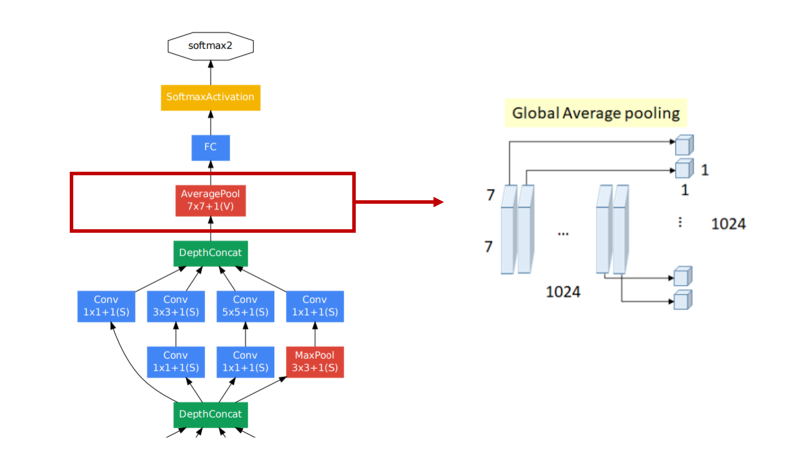
위 그림에선 7x7 feature map이 1024개이므로 분류할 클래스 수가 1024개라고 가정하도록 하겠습니다. GAP는 각 feature map 안에 있는 특징값들의 평균을 구해서 각각의 출력 노드에 바로 입력하는 방식입니다. 파라미터 관점에서 해석해서 보면 위의 Fully Connected 그림의 경우, (7x7x1024)x1024 = 51.3M개의 Weight를 가지고 있고, GAP의 경우 바로 평균을 취하게 되므로 Weight의 개수가 0개가 됩니다.
Auxiliary Classifier
방금까지 위해서 1x1 Conv과 GAP를 살펴보셨는데요. GoogleNet의 다른 특징으로는 바로 Auxiliary Classifier가 존재한다는 점입니다.
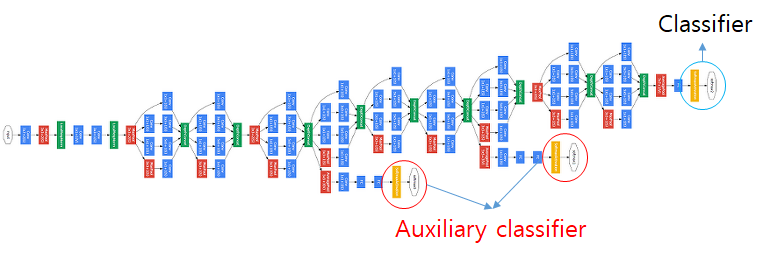
일반적으로 Neural Network은 모델이 점점 깊어질수록 기울기가 소실되는 vanishing gradient의 문제가 생기게됩니다. 그래서 GoogleNet에서는 기존에 사용하던 방법과 같이 Neural Network의 맨 마지막 layer에 softmax를 딱 하나만 놓지 않고, Auxiliary classifier라는 추가적인 classifier를 정의하여 중간에서도 Backpropagation이 진행될 수 있도록 하였습니다.
이때, Backpropagation시, weight값에 큰 영향을 주는 것을 막기 위해 Auxiliary Classifier에 0.3을 곱하여 training을 수행합니다. Auxiliary Classifier는 학습 시 발생하는 문제인 vanishing gradient를 해결하기 위해 사용하는 기법이므로 검증 수행 시 이를 제거하고 제일 마지막 layer의 softmax만을 사용하게 됩니다.
코드 실습
인셉션 모듈을 정의하기 위해 아래 함수들을 미리 정의해두었습니다.
- 1x1 Convolution
- 1x1 Convolution -> 3x3 Convolution
- 1x1 Convolution -> 5x5 Convolution
- 3x3 MaxPooling -> 1x1 Convolution
Define Convolution Blocks
- 1x1 Convolution
1
2
3
4
5
6
def conv_1(in_dim,out_dim):
model = nn.Sequential(
nn.Conv2d(in_dim,out_dim,1,1),
nn.ReLU(),
)
return model
- 1x1 Convolution -> 3x3 Convolution
1
2
3
4
5
6
7
8
def conv_1_3(in_dim,mid_dim,out_dim):
model = nn.Sequential(
nn.Conv2d(in_dim,mid_dim,1,1),
nn.ReLU(),
nn.Conv2d(mid_dim,out_dim,3,1,1),
nn.ReLU()
)
return model
- 1x1 Convolution -> 5x5 Convolution
1
2
3
4
5
6
7
8
def conv_1_5(in_dim,mid_dim,out_dim):
model = nn.Sequential(
nn.Conv2d(in_dim,mid_dim,1,1),
nn.ReLU(),
nn.Conv2d(mid_dim,out_dim,5,1,2),
nn.ReLU()
)
return model
- 3x3 MaxPooling -> 1x1 Convolution
1
2
3
4
5
6
7
def max_3_1(in_dim,out_dim):
model = nn.Sequential(
nn.MaxPool2d(kernel_size=3,stride=1,padding=1),
nn.Conv2d(in_dim,out_dim,1,1),
nn.ReLU(),
)
return model
Define Inception Module
Inception 모듈은 이전 단계에서 정의한 함수들을 활용해서 concat해주는 단계입니다.
- 1x1 Convolution
- 1x1 Convolution -> 3x3 Convolution
- 1x1 Convolution -> 5x5 Convolution
- 3x3 MaxPooling -> 1x1 Convolution
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
class inception_module(nn.Module):
def __init__(self,in_dim,out_dim_1,mid_dim_3,out_dim_3,mid_dim_5,out_dim_5,pool_dim):
super(inception_module,self).__init__()
# 1x1 Convolution
self.conv_1 = conv_1(in_dim,out_dim_1)
# 1x1 Convolution -> 3x3 Convolution
self.conv_1_3 = conv_1_3(in_dim,mid_dim_3,out_dim_3)
# 1x1 Convolution -> 5x5 Convolution
self.conv_1_5 = conv_1_5(in_dim,mid_dim_5,out_dim_5)
# 3x3 MaxPooling -> 1x1 Convolution
self.max_3_1 = max_3_1(in_dim,pool_dim)
def forward(self,x):
out_1 = self.conv_1(x)
out_2 = self.conv_1_3(x)
out_3 = self.conv_1_5(x)
out_4 = self.max_3_1(x)
# concat
output = torch.cat([out_1,out_2,out_3,out_4],1)
return output
Define GoogleNet
GoogleNet은 다음과 같이 구성이 되어 있습니다.
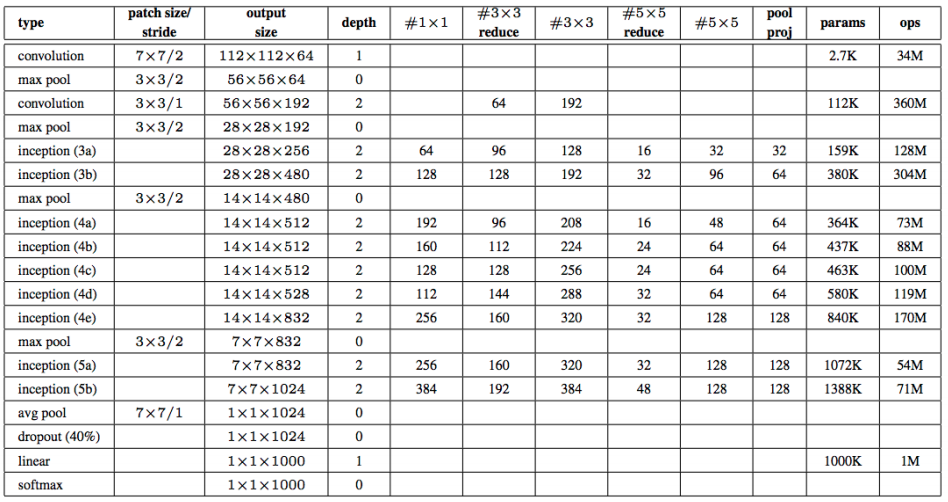
위의 표에서 나온 값들을 입력하여 각각의 dimension을 정의해주면 아래와 같습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
class GoogLeNet(nn.Module):
def __init__(self, base_dim, num_classes=2):
super(GoogLeNet, self).__init__()
self.num_classes=num_classes
self.layer_1 = nn.Sequential(
nn.Conv2d(3,base_dim,7,2,3),
nn.MaxPool2d(3,2,1),
nn.Conv2d(base_dim,base_dim*3,3,1,1),
nn.MaxPool2d(3,2,1),
)
self.layer_2 = nn.Sequential(
inception_module(base_dim*3,64,96,128,16,32,32),
inception_module(base_dim*4,128,128,192,32,96,64),
nn.MaxPool2d(3,2,1),
)
self.layer_3 = nn.Sequential(
inception_module(480,192,96,208,16,48,64),
inception_module(512,160,112,224,24,64,64),
inception_module(512,128,128,256,24,64,64),
inception_module(512,112,144,288,32,64,64),
inception_module(528,256,160,320,32,128,128),
nn.MaxPool2d(3,2,1),
)
self.layer_4 = nn.Sequential(
inception_module(832,256,160,320,32,128,128),
inception_module(832,384,192,384,48,128,128),
nn.AvgPool2d(7,1),
)
self.layer_5 = nn.Dropout2d(0.4)
self.fc_layer = nn.Linear(1024,self.num_classes)
def forward(self, x):
out = self.layer_1(x)
out = self.layer_2(out)
out = self.layer_3(out)
out = self.layer_4(out)
out = self.layer_5(out)
out = out.view(batch_size,-1)
out = self.fc_layer(out)
return out
CIFAR10 Implementation
이전 VGGNet과 마찬가지로 이를 CIFAR10데이터에 적용해보았습니다. TRAIN과 INFERENCE함수는 이전 포스트와 동일합니다. (이전 포스트)
1
2
3
batch_size = 100
learning_rate = 0.0002
num_epoch = 100
TRAIN
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
loss_arr = []
for i in trange(num_epoch):
for j,[image,label] in enumerate(train_loader):
x = image.to(device)
y_= label.to(device)
optimizer.zero_grad()
output = model.forward(x)
loss = loss_func(output,y_)
loss.backward()
optimizer.step()
if i % 10 ==0:
print(loss)
loss_arr.append(loss.cpu().detach().numpy())
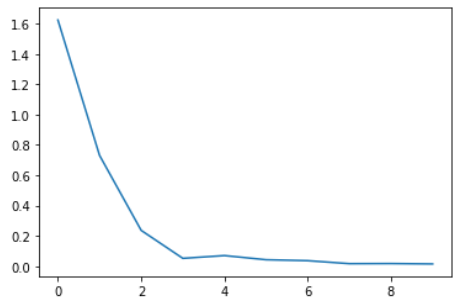
loss 시각화
1
2
plt.plot(loss_arr)
plt.show()
TEST
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
# 맞은 개수, 전체 개수를 저장할 변수를 지정합니다.
correct = 0
total = 0
model.eval()
# 인퍼런스 모드를 위해 no_grad 해줍니다.
with torch.no_grad():
# 테스트로더에서 이미지와 정답을 불러옵니다.
for image,label in test_loader:
# 두 데이터 모두 장치에 올립니다.
x = image.to(device)
y= label.to(device)
# 모델에 데이터를 넣고 결과값을 얻습니다.
output = model.forward(x)
_,output_index = torch.max(output,1)
# 전체 개수 += 라벨의 개수
total += label.size(0)
correct += (output_index == y).sum().float()
# 정확도 도출
print("Accuracy of Test Data: {}%".format(100*correct/total))
Accuracy of Test Data: 71.98999786376953%
긴 글 읽어주셔서 감사합니다 ^~^