[파이토치] 파이토치로 CNN 모델을 구현해보자! (기초편 + DataLoader 사용법)
MNIST 데이터 - CNN 실습
오늘은 MNIST 데이터로 Convolutional Neural Network(이하 CNN)을 구현하고 돌려보는 시간을 갖도록 하겠습니다!
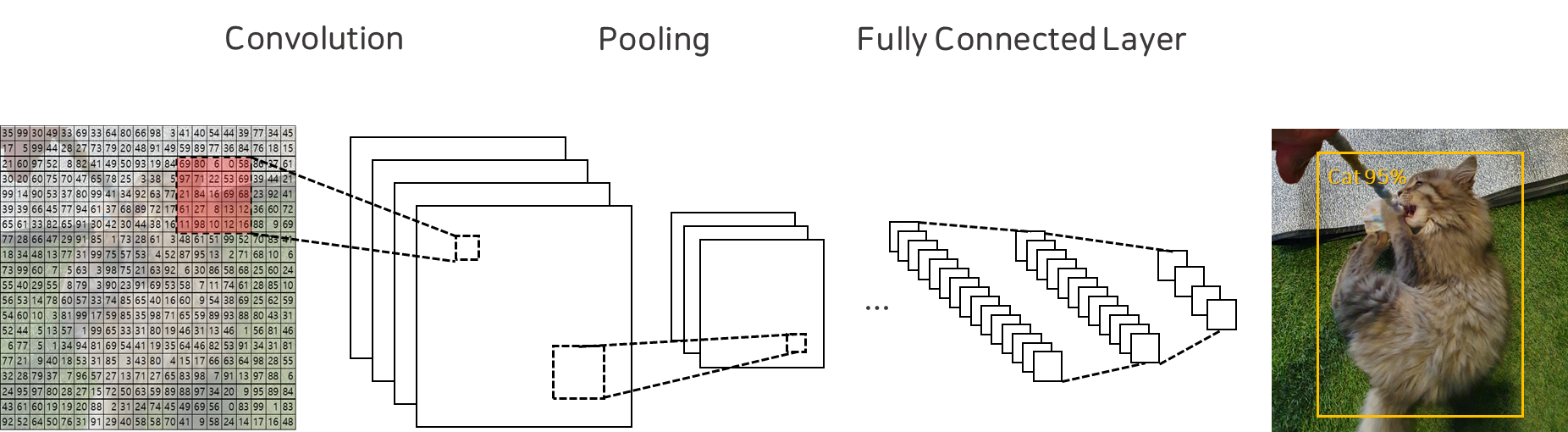
먼저, CNN은 크게 아래와 같은 구성요소로 이루어져 있습니다.
- 합성곱 연산(Convolution) : 이미지의 특성을 추출하는 계층
- 맥스풀링(Max Pooling) : 추출된 특성 중 중요한 정보만을 축약하여 전달
- 완전연결 신경망(Fully Connected Network) : 추출된 정보를 기반으로 최종 예측을 수행하는 계층
Import Library
1
2
3
4
5
6
7
8
9
10
11
12
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.init as init
import torchvision.datasets as datasets
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import numpy as np
import matplotlib.pyplot as plt
Set Hyperparameter
1
2
3
batch_size = 100
learning_rate = 0.0002
num_epoch = 10
Load MNIST Data
1
2
mnist_train = datasets.MNIST(root="../Data/", train=True, transform=transforms.ToTensor(), download=True)
mnist_test = datasets.MNIST(root="../Data/", train=False, transform=transforms.ToTensor(), download=True)
Define Loaders
1
2
train_loader = DataLoader(mnist_train, batch_size=batch_size, shuffle=True, num_workers=2, drop_last=True)
test_loader = DataLoader(mnist_test, batch_size=batch_size, shuffle=False, num_workers=2, drop_last=True)
Define CNN(Base) Model
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.layer = nn.Sequential(
nn.Conv2d(1, 16, 5),
nn.ReLU(),
nn.Conv2d(16, 32, 5),
nn.ReLU(),
nn.MaxPool2d(2, 2),
nn.Conv2d(32, 64, 5),
nn.ReLU(),
nn.MaxPool2d(2, 2)
)
self.fc_layer = nn.Sequential(
nn.Linear(64 * 3 * 3, 100),
nn.ReLU(),
nn.Linear(100, 10)
)
def forward(self, x):
out = self.layer(x)
out = out.view(batch_size, -1)
out = self.fc_layer(out)
return out
Define Device & Model
1
2
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = CNN().to(device)
Define Loss & Optimizer
1
2
loss_func = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
🏋️ Train Model
이제 학습을 시작해보겠습니다. 먼저 모델을 학습 모드로 설정하기 위해 model.train()을 호출합니다.
🔧 model.train()이란?
model.train()은 PyTorch 모델을 학습 모드(training mode)로 전환합니다.
이는 Dropout, BatchNorm 같은 학습 중에만 활성화되는 레이어를 올바르게 동작시키기 위해 필수적으로 호출해야 합니다. 예를 들어:
- Dropout은 학습 시 일부 뉴런을 무작위로 꺼서 과적합을 방지하지만,
- Batch Normalization은 배치의 통계를 사용하여 가중치를 정규화합니다.
model.train()을 호출하지 않으면 이러한 학습 특화 기능이 꺼진 채로 학습이 진행되기 때문에 모델의 성능이 현저히 저하될 수 있습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
loss_arr = []
for i in range(num_epoch):
model.train() # 학습 모드로 전환
for j, [image, label] in enumerate(train_loader):
x = image.to(device)
y = label.to(device)
optimizer.zero_grad()
output = model(x)
loss = loss_func(output, y)
loss.backward()
optimizer.step()
if j % 1000 == 0:
print(f"Epoch {i+1}, Step {j}: Loss = {loss.item():.4f}")
loss_arr.append(loss.cpu().detach().numpy())
🧪 Test Model
학습이 완료된 모델을 바탕으로 테스트 데이터를 입력하여 정확도를 평가해봅니다. 이때는 다음 두 가지 설정을 반드시 적용해야 합니다.
1️⃣ model.eval()이란?
1
model.eval()
- 모델을 평가 모드(Evaluation Mode)로 전환합니다.
- Dropout, BatchNorm 등의 레이어가 학습 시와는 다르게 작동하도록 설정됩니다.
- 예측 시에는 모든 뉴런을 활용하고, BatchNorm은 저장된 평균과 분산을 사용합니다.
즉, 학습과 추론의 모드가 다르기 때문에, 평가 전에 반드시 model.eval()을 호출해야 정확한 성능 평가가 가능합니다.
2️⃣ with torch.no_grad()란?
1
with torch.no_grad():
- Pytorch의 Autograd 엔진을 꺼서 gradient 계산을 하지 않도록 설정합니다.
- 테스트나 추론 시에는 기울기 계산이 필요 없기 때문에 메모리와 속도 측면에서 효율적입니다.
- 또한, GPU 메모리를 절약하고 연산 속도를 높일 수 있습니다.
✅ 전체 테스트 코드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
correct = 0
total = 0
model.eval() # 평가 모드로 전환
with torch.no_grad(): # gradient 비활성화
for image, label in test_loader:
x = image.to(device)
y = label.to(device)
output = model(x)
_, output_index = torch.max(output, 1)
total += label.size(0)
correct += (output_index == y).sum().float()
print("Accuracy of Test Data: {:.2f}%".format(100 * correct / total))
마무리 📝
이번 포스트에서는 MNIST 데이터셋을 활용해 CNN 모델을 구성하고 학습부터 테스트까지 전 과정을 진행해보았습니다.
특히, PyTorch에서 모델의 학습과 평가 시점에 따라 반드시 호출해야 하는 model.train(), model.eval(), torch.no_grad()의 의미와 역할을 명확히 이해하는 것이 매우 중요합니다.
이러한 기본적인 흐름을 잘 익혀두면, 향후 복잡한 모델에서도 훨씬 효율적으로 실험을 진행할 수 있게 됩니다 😊
궁금하신 점이 있다면 댓글로 남겨주세요 🙌
긴 글 읽어주셔서 감사합니다!