[Paper Review] K-EXAONE Technical Report
도입: 한국 AI 생태계의 도전과 K-EXAONE의 탄생
글로벌 대규모 언어 모델(LLM) 개발 경쟁이 치열해지고 있습니다. Closed-Source 모델이 여전히 성능 우위를 점하고 있지만, Open-Weight 모델들이 수천억 파라미터를 넘어 조(trillion) 단위 스케일로 공격적으로 확장하며 그 격차를 빠르게 좁히고 있습니다.
그러나 한국의 상황은 독특한 도전을 안고 있습니다. 글로벌 선두 국가 대비 AI 전용 데이터센터와 AI 칩이 상대적으로 부족하여, 그간 수백억(tens of billions) 파라미터 수준의 비용 효율적 소규모 모델 개발에 집중해왔습니다. 하지만 AI 전환의 근본적 기반을 확보하려면 글로벌 최상위 수준의 성능을 갖춘 대규모 모델이 필수적입니다. 이러한 인프라 격차를 해소하기 위해 한국 정부가 GPU 등 핵심 자원을 제공하는 전략적 프로그램을 시작했고, LG AI Research가 이 지원을 활용하여 개발한 것이 바로 K-EXAONE입니다.
K-EXAONE은 이전 모델인 EXAONE 4.0의 하이브리드 아키텍처(추론/비추론 통합)를 계승하면서, 세 가지 핵심 혁신을 도입합니다. 첫째, Mixture-of-Experts(MoE) 패러다임을 채택하여 총 236B 파라미터 중 추론 시 23B만 활성화하는 효율적 스케일링을 달성합니다. 둘째, 기존 3개 언어(한국어, 영어, 스페인어)에서 독일어, 일본어, 베트남어를 추가하여 6개 언어로 다국어 커버리지를 확장합니다. 셋째, 256K 토큰의 Context Window를 지원하여 실세계 Long-Context 애플리케이션에 대응합니다.
모델 아키텍처 설계
Fine-Grained Sparse MoE: 표현력과 효율의 양립
K-EXAONE은 기존 EXAONE 시리즈의 Dense 모델링 패러다임에서 벗어나, 100B+ 규모 모델 학습에서 점점 보편화되고 있는 MoE 아키텍처를 채택합니다. 핵심 설계 철학은 높은 표현 다양성과 자원 효율적 학습/추론의 양립입니다.
구체적으로, 128개의 Expert 풀에서 토큰당 Top-8 Expert를 라우팅하고, 여기에 1개의 Shared Expert를 추가하여 총 9개의 Expert가 동시에 활성화됩니다. 총 파라미터가 236B이지만 활성 파라미터는 약 23B에 불과하여, Dense 모델 대비 훨씬 효율적인 연산이 가능합니다.
MoE 구조에서 핵심적인 라우팅 안정성과 Expert 활용 효율을 위해 두 가지 기법을 적용합니다. Sequence-Level Load Balancing은 특정 Expert에 토큰이 편중되는 것을 방지하며, Dropless Routing Policy는 모든 토큰이 Capacity 제한 없이 Expert에 디스패치되도록 보장합니다. 이 두 기법의 조합은 대규모 MoE 학습에서 Gradient Flow를 안정화하고 수렴 행동을 개선하는 데 핵심적입니다.
Hybrid Attention과 블록 구조
K-EXAONE의 Main Block은 총 48개 레이어로 구성되며, Sliding Window Attention(SWA) 36개 레이어와 Global Attention(GA) 12개 레이어가 혼합된 Hybrid Attention 구조를 따릅니다. 전체 레이어에 GA를 적용하는 것 대비 메모리 소비와 연산 오버헤드를 크게 줄이면서도 Long-Context 모델링 능력을 유지하는 설계입니다.
블록 구조의 흐름을 텍스트로 표현하면 다음과 같습니다.
1
2
3
4
5
6
7
8
입력 토큰 → Embedding
→ [SWA + Sparse MoE] × 3 레이어
→ [GA + Sparse MoE] × 1 + [SWA + Sparse MoE] × 3 반복 × 12
→ [GA + Sparse MoE] × 1
→ RMSNorm → LM Head → 출력
* 각 블록 내부: Attention → RMSNorm → Sparse MoE (128 experts, top-8 + 1 shared) → RMSNorm
* 첫 번째 레이어만 MoE 대신 Dense FFN (hidden size: 18,432) → 학습 안정성 확보
여기서 주목할 설계 결정이 몇 가지 있습니다. 첫 번째 레이어를 Dense FFN으로 구현한 것은 MoE 학습 초기의 불안정성을 방지하기 위한 선택입니다. SWA의 Window Size를 기존 4,096에서 128로 대폭 축소한 것은 Long-Context 추론 시 KV-Cache 사용량을 극단적으로 줄이면서도 모델링 용량을 보존하기 위한 것입니다. Attention Head는 Query 64개, Key-Value 8개의 Grouped Query Attention(GQA) 구성이며, Head Dimension은 128입니다.
학습 안정성과 Long-Context 외삽을 강화하기 위해 EXAONE 4.0에서 두 가지 기법을 계승합니다. QK Norm은 Attention 연산 전에 Query/Key 벡터에 Layer Normalization을 적용하여, 깊은 네트워크에서 Attention Logit이 폭발하는 문제를 방지합니다. SWA-only RoPE는 Rotary Positional Embeddings를 SWA 레이어에만 선택적으로 적용하여, GA에서의 글로벌 토큰 상호작용에 대한 간섭을 방지하고 Long-Sequence 외삽 견고성을 높입니다.
Multi-Token Prediction(MTP) 모듈
K-EXAONE은 Dense Layer 기반의 MTP 모듈을 통합하여 현재 토큰뿐 아니라 xt+1x_{t+1}xt+1 미래 토큰까지 예측하는 보조 학습 목표를 적용합니다. 이 모듈의 역할은 이중적입니다. 학습 시에는 Future-Token 예측 능력을 향상시키는 Auxiliary Loss로 기능하고, 추론 시에는 Self-Drafting에 활용되어 표준 Autoregressive Decoding 대비 약 1.5배의 디코딩 처리량 향상을 달성합니다.
MTP Block 자체의 파라미터 수는 0.52B으로 매우 경량이며, Dense Layer 기반 설계를 통해 라우팅 오버헤드와 메모리 소비를 최소화합니다. MTP Block은 Main Block의 LM Head와 Embedding을 공유(shared)하여 추가적인 파라미터 부담을 줄입니다.
아키텍처 구성 요약
| 구성 요소 | 세부 설정 | 값 |
|---|---|---|
| Main Block | Layers (Total / SWA / GA) | 48 / 36 / 12 |
| Sliding Window Size | 128 | |
| Attention Heads (Q / KV) | 64 / 8 | |
| Head Dimension | 128 | |
| Experts (Total / Shared / Activated) | 128 / 1 / 8 | |
| Parameters (Total / Activated) | 236B / 23B | |
| MTP Block | Attention Heads (Q / KV) | 64 / 8 |
| Head Dimension | 128 | |
| Parameters | 0.52B |
Tokenizer 재설계: SuperBPE와 150K 어휘
K-EXAONE은 Tokenizer를 전면 재설계하여 Vocabulary Size를 기존 100K에서 150K로 확장합니다. 설계 전략의 핵심은 기존 어휘의 고빈도 70%를 보존하면서, 나머지 용량을 추가 언어, STEM(Science, Technology, Engineering, Mathematics), 코드 도메인으로 재배분하는 것입니다.
특히 SuperBPE 전략을 도입하여 빈번한 단어 시퀀스를 단일 토큰(Superword)으로 인코딩합니다. 이 Superword Token은 전체 어휘의 약 20%를 차지하며, 영어:한국어:다국어 = 2:3:1 비율로 할당됩니다. 한국어에 가장 높은 비중을 둔 점이 Sovereign AI로서의 설계 의도를 반영합니다.
추가적으로 Pre-Tokenization Regex를 업데이트하여 Superword 경계, 줄바꿈, 다국어 유니코드 문자를 처리하고, Unicode Normalization을 NFKC에서 NFC로 전환합니다. NFC 전환의 이유는 코드 및 STEM 코퍼스에서 흔히 발견되는 위첨자, 아래첨자, 기호가 많은 텍스트의 의미적 구분을 보존하기 위한 것입니다.
결과적으로 Bytes per Token 기준으로 전 도메인에서 평균 약 30%의 토큰 효율성 향상을 달성합니다. 도메인별로는 다국어에서 +49.8%, 한국어에서 +29.0%, 코드에서 +26.7%, STEM에서 +20.1%, 영어에서 +19.6%의 개선을 보입니다.
학습 파이프라인
Pre-training: 3단계 커리큘럼
K-EXAONE은 총 11T 토큰, 1.52×10241.52 \times 10^{24}1.52×1024 FLOPs 규모의 사전학습을 수행하며, 3단계 커리큘럼을 통해 기초 지식 → 도메인 전문성 → 추론 능력을 점진적으로 구축합니다. EXAONE 4.0의 데이터 파이프라인을 계승하면서 다중 데이터 필터링을 적용하여 고품질 데이터를 확보합니다.
학습 셋업에서 주목할 점은 FP8 정밀도로 네이티브 학습을 수행하면서도 BF16과 동등한 학습 Loss 곡선을 달성했다는 것입니다. 이는 FP8 학습이 최적화 안정성을 보존하면서도 Full Quantization-Aware 수렴이 가능함을 보여줍니다. Optimizer로는 Muon을 채택하고, Learning Rate Scheduler는 Warmup-Stable-Decay(WSD)를 사용합니다. 주요 하이퍼파라미터는 최대 학습률 3.0×10−43.0 \times 10^{-4}3.0×10−4, MoE Sequence Auxiliary Loss 계수 1.0×10−41.0 \times 10^{-4}1.0×10−4, Expert Bias Update Factor 1.0×10−41.0 \times 10^{-4}1.0×10−4, MTP Loss Weight 0.05입니다.
다국어 확장을 위해서는 Cross-Lingual Knowledge Transfer를 활용한 합성 코퍼스를 생성합니다. 언어별 사전학습 데이터 분포가 크게 다르기 때문에, 전문 지식과 추론 패턴을 언어 간에 전파하는 Synthetic Corpora를 생성하여 입력 언어에 관계없이 균일한 성능을 보장합니다.
또한 Thinking-Augmented Data Synthesis를 통해 사전학습 데이터에 명시적 추론 감독을 포함시킵니다. 문서 기반의 Thinking Trajectory를 생성하고 이를 소스 콘텐츠와 결합하여, 단계별 추론을 인코딩하는 통합 샘플을 만듭니다. 이러한 Thinking-Augmented 코퍼스는 추론 행동의 전이를 촉진하고 후속 Post-Training의 효과를 높이는 전략입니다.
Context Length Extension: 8K → 32K → 256K
K-EXAONE은 2단계 Context Length Extension을 통해 최대 256K 토큰을 지원합니다. 기본 모델은 8K 토큰으로 사전학습된 후, Stage 1에서 8K → 32K, Stage 2에서 32K → 256K로 확장됩니다. 두 단계 모두 동일한 세 가지 데이터 구성 요소를 공유하되, 각 단계의 목표와 안정성 요구에 맞게 샘플링 비율을 조정합니다.
Rehearsal Dataset은 Long-Context 특화 학습의 가장 큰 위험인 Short-Context 성능 저하를 방지하기 위한 핵심 구성 요소입니다. 사전학습 분포에서 추출한 고품질 샘플을 포함하여, 짧은 Context에서의 모델 행동을 앵커링하는 일관된 학습 신호를 제공합니다. 두 Stage 모두에 포함되되, Stage별로 비율을 조정하여 Long-Context 학습 신호가 충분히 반영되도록 합니다.
Synthetic Reasoning Dataset은 수학, 과학, 경쟁 프로그래밍의 도전적 문제로 구성되며, 최종 답변뿐 아니라 중간 추론 패턴 학습을 장려하는 합성 추론 콘텐츠를 포함합니다. 이 데이터셋은 Context Extension 전 과정에 걸쳐 통합되어, 긴 입력 하에서도 추론 품질이 향상되도록 합니다.
Long-Document Dataset은 단일 학습 인스턴스 내에서 소비될 수 있는 전체 문서 시퀀스로 구성됩니다. 전체 Long-Document를 Truncation 없이 End-to-End로 학습하여 Long-Range Dependency 포착을 장려합니다. Stage 1에서는 32K까지의 안정적 성능에 우선순위를 두고, Stage 2에서는 256K까지의 의존성을 모델링하기 위해 Long-Document 샘플의 비중을 높입니다.
품질 검증을 위해 사전학습과 동일한 프로토콜의 Short-Context 평가와 Needle-In-A-Haystack(NIAH) 테스트를 체계적으로 수행합니다. 각 Stage의 목표 Context Range에서 거의 완벽한 NIAH 성능(“green light”)을 달성할 때까지 학습을 반복하며, 이를 통해 K-EXAONE이 전반적 성능 저하 없이 256K 토큰으로 성공적으로 확장되었음을 확인합니다.
Post-training: SFT → RL → Preference Learning
Post-training은 세 단계로 구성됩니다. 첫째, 대규모 Supervised Fine-Tuning(SFT)을 통해 다양한 사용자 지시를 따르고 응답을 생성하는 능력을 학습합니다. 태스크를 여러 도메인으로 분류하고 각각에 맞는 생성 방법이나 전문가를 채택합니다. 한국어 특화 능력 강화를 위해 과학기술정보통신부(MSIT)와 한국지능정보사회진흥원(NIA), 한국데이터산업진흥원(K-DATA) 등이 제공하는 공공 및 기관 데이터를 활용합니다.
Agentic Tool Use 학습에서는 실제 Tool 환경 구축의 높은 비용과 비효율성을 극복하기 위해 LLM을 활용한 Synthetic Tool Environment를 구축합니다. Tool-Use 시나리오와 검증 가능한 통과 기준을 포함하는 합성 환경을 생성한 뒤, LLM으로 평가하여 비현실적이거나 풀 수 없는 케이스를 필터링합니다. 이 과정을 통해 수백 개의 검증 가능하고 현실적인 Tool-Use Task와 평가 환경을 확보합니다.
Web Search 수행 시에는 두 가지 Sub-Agent를 활용하여 Context 효율성을 개선합니다. Summarizer Sub-Agent는 가져온 웹페이지를 요약하여 K-EXAONE이 길고 노이즈가 많은 웹 텍스트를 직접 처리하지 않도록 합니다. Trajectory Compressor는 Tool-Calling 이력이 사전 정의된 단계 수를 초과하면, 전체 상호작용을 Tool 출력의 핵심 사실과 남은 조사 질문을 담은 단일 JSON 구조화 레코드로 압축합니다. 이 설계는 중복된 Tool 결과가 K-EXAONE에 반복 노출되는 것을 방지합니다. 두 Sub-Agent 모두 추론 시 K-EXAONE과 동일한 기반 모델로 구현됩니다.
Reinforcement Learning: AGAPO
추론 능력을 강화하기 위해 Verifiable Rewards를 사용한 Reinforcement Learning(RL)을 수행합니다. 수학, 코드, STEM, Instruction Following을 아우르는 Multi-Task 설정에서 학습하며, 검증에는 Rule-Based Verifier와 LLM-as-a-Judge의 조합을 사용합니다.
최적화에는 Off-Policy Policy Gradient와 Truncated Importance Sampling을 사용하는 AGAPO를 채택합니다. RL 목적함수는 다음과 같이 정의됩니다. 질문 q∼P(Q)q \sim P(Q)q∼P(Q)에 대해 Rollout Policy πθrollout\pi_{\theta_{\text{rollout}}}πθrollout에서 GGG개의 후보 응답 O={o1,…,oG}O = {o_1, \ldots, o_G}O={o1,…,oG}를 샘플링하고, 각 응답에 검증 가능한 보상 ri∈[0,1]r_i \in [0, 1]ri∈[0,1]을 부여합니다.
| JAGAPO(θ)=Eq∼P(Q),{oi}i=1G∼πθrollout(O∣q)[1G∑i=1G(1∣oi∣∑t=1∣oi∣sg(min(ρi,t,ϵ))Aglobal,ilogπθ(oi,t∣q,oi,<t))]J_{\text{AGAPO}}(\theta) = \mathbb{E}_{q \sim P(Q), {o_i}_{i=1}^{G} \sim \pi_{\theta_{\text{rollout}}}(O | q)}\left[\frac{1}{G}\sum_{i=1}^{G}\left(\frac{1}{ | o_i | }\sum_{t=1}^{ | o_i | } \text{sg}\left(\min(\rho_{i,t}, \epsilon)\right) A_{\text{global},i} \log\pi_\theta(o_{i,t} | q, o_{i,<t})\right)\right]JAGAPO(θ)=Eq∼P(Q),{oi}i=1G∼πθrollout(O∣q)[G1∑i=1G(∣oi∣1∑t=1∣oi∣sg(min(ρi,t,ϵ))Aglobal,ilogπθ(oi,t∣q,oi,<t))] |
여기서 Importance Ratio와 Advantage는 다음과 같이 계산됩니다.
| ρi,t=πθ(oi,t∣q,oi,<t)πθrollout(oi,t∣q,oi,<t)\rho_{i,t} = \frac{\pi_\theta(o_{i,t} | q, o_{i,<t})}{\pi_{\theta_{\text{rollout}}}(o_{i,t} | q, o_{i,<t})}ρi,t=πθrollout(oi,t∣q,oi,<t)πθ(oi,t∣q,oi,<t) |
Agroup,i=ri−1G−1∑j≠irj,Aglobal,i=Agroup,i−mean({Agroup,k}k)std({Agroup,k}k)A_{\text{group},i} = r_i - \frac{1}{G-1}\sum_{j \neq i} r_j, \quad A_{\text{global},i} = \frac{A_{\text{group},i} - \text{mean}({A_{\text{group},k}}_k)}{\text{std}({A_{\text{group},k}}_k)}Agroup,i=ri−G−11∑j=irj,Aglobal,i=std({Agroup,k}k)Agroup,i−mean({Agroup,k}k)
Group-Level Advantage를 먼저 계산하여 그룹 내 상대적 보상 신호를 포착한 뒤, Global Normalization을 적용하여 배치 수준의 정보를 반영합니다. 핵심 설계 결정으로는 Zero-Variance Filtering(샘플링된 Rollout이 모두 동일한 보상을 받는 프롬프트를 제거하여 Advantage가 0이 되는 경우를 방지), KL Penalty 제거(성능 향상과 불필요한 연산 방지), MoE Router 동결(RL 학습 전 과정에서 라우터를 고정)이 있습니다.
Preference Learning: GROUPER
RL 학습 후에는 Human Preference와의 정렬을 위한 Preference Learning 단계를 수행합니다. 이 단계에서는 추론 성능을 보존하면서 Chat, Safety, Instruction Following, Agentic Tool Use, Creative Writing 등 일반 정렬 도메인에 집중합니다. 이를 위해 SimPER의 개선 변형인 GROUPER(Group-wise SimPER)를 제안합니다.
GRPO에서 영감을 받아, 각 쿼리에 대해 여러 응답을 샘플링하고 Group-wise Advantage로 학습합니다. 각 응답의 Preference Reward는 Rule-Based Reward와 다차원 평가를 수행하는 Rubric-Based Generative Reward의 조합으로 계산됩니다. 목적함수는 다음과 같습니다.
| LGROUPER(θ)=−Ex∼P(X),{oi}i=1G∼πθinit(O∣x)[1G∑i=1G(Apref,iexp(1∣oi∣logπθ(oi∣x)))]\mathcal{L}_{\text{GROUPER}}(\theta) = -\mathbb{E}_{x \sim P(X), {o_i}_{i=1}^{G} \sim \pi_{\theta_{\text{init}}}(O | x)}\left[\frac{1}{G}\sum_{i=1}^{G}\left(A_{\text{pref},i} \exp\left(\frac{1}{ | o_i | }\log\pi_\theta(o_i | x)\right)\right)\right]LGROUPER(θ)=−Ex∼P(X),{oi}i=1G∼πθinit(O∣x)[G1∑i=1G(Apref,iexp(∣oi∣1logπθ(oi∣x)))] |
Advantage 계산은 Preference Reward를 표준화한 뒤 [−1,1][-1, 1][−1,1] 범위로 스케일링합니다.
zi=rpref,i−mean({rpref,j}j=1G)std({rpref,j}j=1G),Apref,i=2⋅zi−min({zj}j=1G)max({zj}j=1G)−min({zj}j=1G)−1∈[−1,1]z_i = \frac{r_{\text{pref},i} - \text{mean}({r_{\text{pref},j}}_{j=1}^{G})}{\text{std}({r_{\text{pref},j}}_{j=1}^{G})}, \quad A_{\text{pref},i} = 2 \cdot \frac{z_i - \min({z_j}_{j=1}^{G})}{\max({z_j}_{j=1}^{G}) - \min({z_j}_{j=1}^{G})} - 1 \in [-1, 1]zi=std({rpref,j}j=1G)rpref,i−mean({rpref,j}j=1G),Apref,i=2⋅max({zj}j=1G)−min({zj}j=1G)zi−min({zj}j=1G)−1∈[−1,1]
GROUPER는 SimPER의 Hyperparameter-Free 특성과 GRPO의 Group-wise Sampling을 결합하여, 일반 도메인에서의 정렬 성능을 개선합니다.
Data Compliance
AI 모델 개발에 필요한 대규모 데이터의 수집과 활용 과정에서 발생할 수 있는 저작권 침해, 지적재산권 침해, 개인정보 보호 위반 등의 법적 리스크를 최소화하기 위해, LG AI Research는 데이터 수집, AI 모델 학습, 정보 제공의 전 과정에 걸쳐 AI Compliance 리뷰를 수행합니다.
평가 결과
벤치마크와 평가 설정
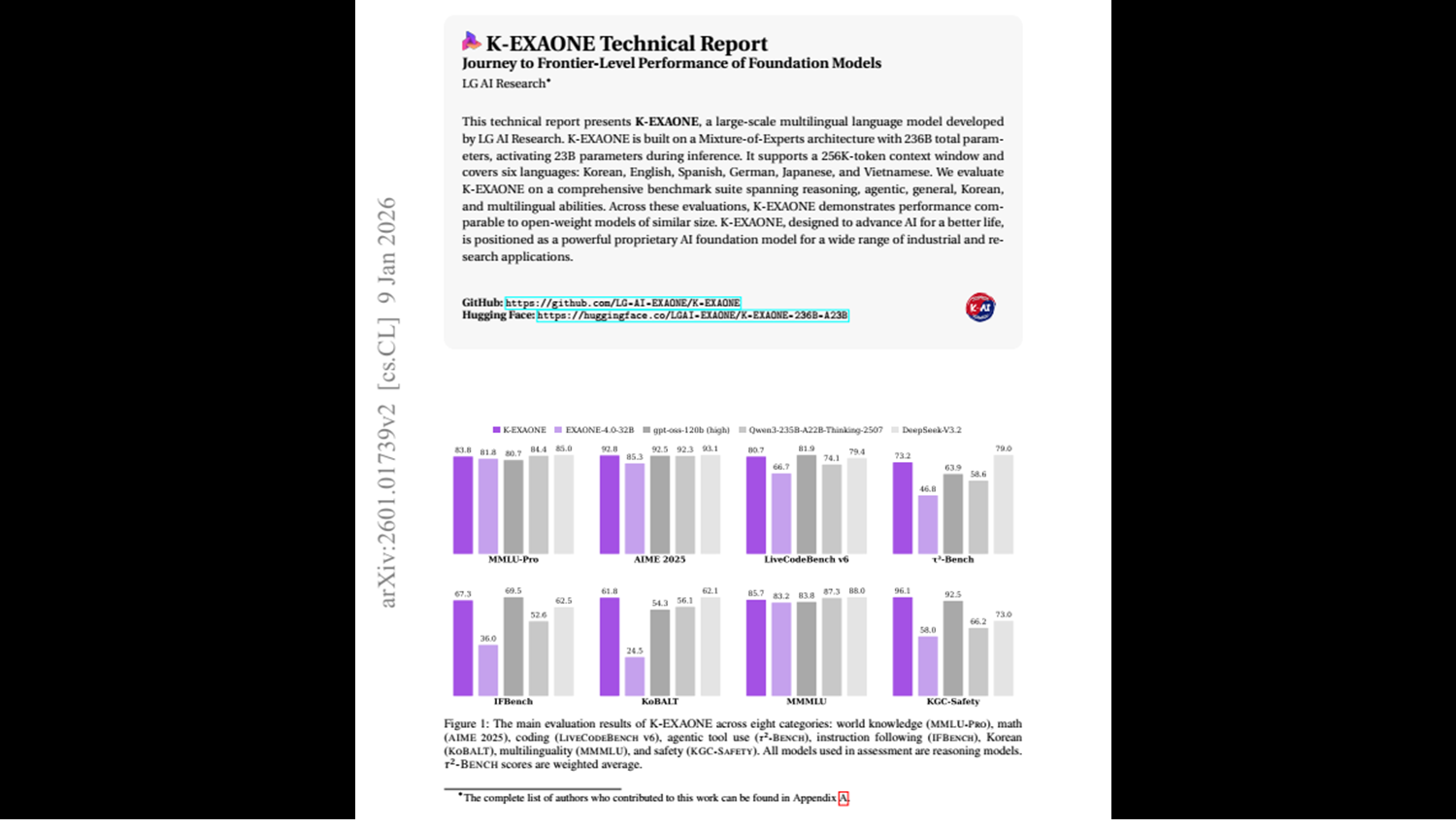
K-EXAONE은 9개 카테고리에 걸친 포괄적 벤치마크 스위트로 평가됩니다. World Knowledge(MMLU-PRO, GPQA-DIAMOND, HUMANITY’S LAST EXAM), Math(IMO-ANSWERBENCH, AIME 2025, HMMT NOV 2025), Coding/Agentic Coding(LIVECODEBENCH PRO, LIVECODEBENCH V6, TERMINAL-BENCH 2.0, SWE-BENCH VERIFIED), Agentic Tool Use(τ2\tau^2τ2-BENCH, BROWSECOMP), Instruction Following(IFBENCH, IFEVAL), Long Context Understanding(AA-LCR, OPENAI-MRCR), Korean(KMMLU-PRO, KOBALT, CLICK, HRM8K, KO-LONGBENCH), Multilinguality(MMMLU, WMT24++), Safety(WILDJAILBREAK, KGC-SAFETY)를 포함합니다.
평가 설정은 Temperature 1.0, Top-p 0.95이며, Long Context Understanding 벤치마크에는 160K, 나머지에는 128K Context Length를 사용합니다. 추론 시 MTP는 비활성화합니다.
Reasoning 모드 주요 결과
비교 대상은 EXAONE 4.0(32B Dense), gpt-oss-120b(117B MoE, 5.1B Active), Qwen3-235B-A22B-Thinking-2507(235B MoE, 22B Active), DeepSeek-V3.2(671B MoE, 37B Active)입니다.
| 벤치마크 | K-EXAONE | EXAONE 4.0 | gpt-oss-120b | Qwen3-235B | DeepSeek-V3.2 |
|---|---|---|---|---|---|
| MMLU-PRO | 83.8 | 81.8 | 80.7 | 84.4 | 85.0 |
| AIME 2025 | 92.8 | 85.3 | 92.5 | 92.3 | 93.1 |
| LiveCodeBench V6 | 80.7 | 66.7 | 81.9 | 74.1 | 79.4 |
| τ2\tau^2τ2-Bench (weighted) | 73.2 | 46.8 | 63.9 | 58.6 | 79.0 |
| IFBench | 67.3 | 36.0 | 69.5 | 52.6 | 62.5 |
| KoBALT | 61.8 | 25.4 | 54.3 | 56.1 | 62.7 |
| KGC-SAFETY | 96.1 | 58.0 | 92.5 | 66.2 | 73.0 |
수학 추론에서 K-EXAONE은 AIME 2025에서 92.8을 달성하여 gpt-oss-120b(92.5)와 Qwen3(92.3)을 상회하고, 37B 활성 파라미터를 가진 DeepSeek-V3.2(93.1)에 근접합니다. 23B 활성 파라미터로 이 수준의 성능을 달성한 것은 파라미터 효율성 면에서 인상적입니다.
Agentic Tool Use(τ2\tau^2τ2-Bench)에서는 가중 평균 73.2로 gpt-oss-120b(63.9)와 Qwen3(58.6)을 크게 상회합니다. 이는 Synthetic Tool Environment 기반 학습 전략이 유효했음을 시사합니다. 다만 DeepSeek-V3.2(79.0)에는 미치지 못합니다.
Instruction Following에서 K-EXAONE은 IFBench 67.3, IFEVAL 89.7을 기록하여 대부분의 비교 모델을 능가합니다.
안전성(KGC-SAFETY)에서는 96.1로 모든 비교 모델을 압도적으로 능가합니다. gpt-oss-120b(92.5)와도 3.6p 차이를 보이며, Qwen3(66.2)와 DeepSeek-V3.2(73.0)와는 20~30p 이상의 격차를 보입니다.
한국어 및 다국어 성능
한국어 벤치마크에서 K-EXAONE은 Open-Weight Reasoning 모델 중 강한 성능을 보입니다. CLICK(언어·문화 역량) 83.9, HRM8K(올림피아드급 수학 추론) 90.9, KO-LONGBENCH(Long-Context 이해) 86.8을 달성합니다. 다만 KMMLU-PRO(67.3)에서 Qwen3(71.6)과 DeepSeek-V3.2(72.1)에 뒤처지는 점은 주목할 만합니다. 한국어 특화 모델임에도 한국어 전문 지식 벤치마크에서 최고가 아닌 것은 향후 개선이 필요한 영역입니다.
다국어 평가에서는 MMMLU 85.7, WMT24++ 90.5를 기록합니다. EXAONE 4.0 대비 모든 언어에서 고르게 성능이 향상되어, 특정 언어의 두드러진 약화나 지배 없이 균형 잡힌 다국어 역량을 보여줍니다.
Non-Reasoning 모드 특기사항
Non-Reasoning 모드에서 특히 주목할 결과는 Long Context Understanding입니다. K-EXAONE은 AA-LCR 45.2, OPENAI-MRCR 60.9를 달성하여, Qwen3(31.2, 42.8)과 DeepSeek-V3.2(32.0, 42.4)를 대폭 상회합니다. 이는 Hybrid Attention 구조와 2단계 Context Extension 전략이 Non-Reasoning 환경에서 특히 효과적임을 시사합니다.
EXAONE 4.0 대비 개선폭
EXAONE 4.0(32B Dense)에서 K-EXAONE(236B MoE, 23B Active)으로의 전환에서 가장 극적인 개선이 나타난 영역은 τ2\tau^2τ2-Bench Telecom(23.7 → 73.5, +49.8p), KGC-SAFETY(58.0 → 96.1, +38.1p), KoBALT(25.4 → 61.8, +36.4p), IFBench(36.0 → 67.3, +31.3p)입니다. 이는 MoE 스케일링과 Post-Training 파이프라인 개선의 복합적 효과로 해석됩니다.
개선 여지 영역
실험 결과에서 몇 가지 개선 여지가 확인됩니다. Agentic Coding(SWE-BENCH VERIFIED 49.4)에서 DeepSeek-V3.2(73.1)과 gpt-oss-120b(62.4)에 비해 상당한 격차가 존재합니다. HUMANITY’S LAST EXAM(13.6)에서 DeepSeek-V3.2(25.1)의 약 절반 수준으로, 최상위 난이도 지식 추론에서 한계를 보입니다.
안전성 프레임워크: K-AUT와 KGC-SAFETY
K-EXAONE의 가장 두드러진 차별점 중 하나는 한국 사회문화적 맥락을 체계적으로 반영한 안전성 프레임워크입니다. 기존의 서구 중심 AI 위험 분류 체계가 한국 사회의 문화적 민감성과 맥락 특화 요구를 충분히 반영하지 못하는 한계를 극복하기 위해, Korea-Augmented Universal Taxonomy(K-AUT)를 제안합니다.
K-AUT는 4개 주요 도메인과 226개 세부 위험 영역으로 구성됩니다. Universal Human Values(55개)는 UN 헌장과 국제 인권 기준에 기반한 생명·존엄·기본권 위협을 다룹니다. Social Safety(75개)는 사회 질서 교란이나 양극화 심화를 평가합니다. Korean Sensitivity(60개)는 헌법적 가치, 국내법(국가보안법 등), 검증된 역사적 합의에 기반하여 한국의 문화적·역사적·지정학적 맥락에서의 민감 이슈를 관리합니다. Future Risk(36개)는 국제 AI 윤리 원칙과 예측적 위험 연구에 기반하여 신기술로 인한 새로운 위협을 다룹니다.
이 프레임워크를 기반으로 한 KGC-SAFETY 벤치마크는 226개 카테고리에서 각 10개씩 총 2,260개 테스트 인스턴스로 구성되며, 다국어(6개 언어), 멀티턴, 적대적, 일반 시나리오를 포함합니다. 평가는 LLM-as-a-Judge 프레임워크로 수행되며, 각 테스트 케이스의 안전 여부를 이진 판단합니다.
KGC-SAFETY 세부 결과에서 대부분의 모델이 Universal Human Values와 Social Safety에서 상대적으로 높은 Safe Rate를 보이지만, Future Risk와 Korean Sensitivity에서는 낮은 경향을 보입니다. K-EXAONE은 전 도메인에서 94% 이상의 Safe Rate를 유지하여(Universal Human Values 97.5, Social Safety 96.9, Korean Sensitivity 94.3, Future Risk 95.0), K-AUT 기반의 한국 특화 안전성 학습이 효과적이었음을 입증합니다.
논문에서는 이 접근법이 다른 국가의 Sovereign AI 개발 시 modular하고 scalable한 blueprint으로 활용될 수 있다고 위치를 지정합니다. 보편적 윤리에 지역적 특수성을 체계적으로 통합하는 K-AUT의 구조는, 각국의 문화적 맥락에 맞게 확장 가능한 설계를 갖추고 있습니다.
한계와 배포
K-EXAONE은 모든 LLM과 마찬가지로 몇 가지 한계를 가집니다. 개인적, 유해한, 편향된 정보를 포함하는 부적절한 응답이 생성될 수 있으며, 연령·성별·인종 등과 관련된 편향된 응답이 나올 수 있습니다. 학습 데이터의 통계에 크게 의존하여 의미적·구문적으로 부정확한 문장이 생성될 수 있고, 최신 정보를 반영하지 못하여 거짓이거나 모순된 응답을 할 수 있습니다.
배포 측면에서 K-EXAONE은 비독점적, 비양도적, 전 세계적, 취소 불가 라이선스로 상업적·비상업적 목적의 접근, 다운로드, 설치, 수정, 사용, 배포, 파생 저작물 생성이 허용됩니다. 다만 상업적 목적의 배포, 서브라이선싱, 또는 제3자 제공은 별도 합의가 필요합니다.
결론
K-EXAONE은 한국의 AI 인프라 제약 속에서 정부-민간 협력을 통해 글로벌 경쟁력 있는 대규모 모델을 구축할 수 있음을 실증한 Sovereign AI 모델입니다. MoE 아키텍처를 통한 효율적 스케일링(236B/23B), Hybrid Attention 기반의 256K Long-Context 처리, SuperBPE Tokenizer의 평균 30% 효율 향상, AGAPO RL과 GROUPER Preference Learning을 통한 정렬, 그리고 K-AUT 프레임워크 기반의 한국 사회문화 특화 안전성이라는 다층적 혁신이 조화를 이루며, 추론, Agentic, 다국어, 안전성 등 다양한 평가에서 유사 규모 Open-Weight 모델들과 대등하거나 그 이상의 성능을 입증합니다.
향후 연구 방향으로는 K-EXAONE의 MoE 라우팅 동작 분석(어떤 Expert가 어떤 언어/도메인에 특화되는지에 대한 Ablation Study), Agentic Coding 능력 강화, 그리고 GROUPER와 기존 RLHF/DPO 계열 Preference Learning 방법론 간의 심층 비교가 흥미로운 탐구 주제가 될 것입니다.
읽어주셔서 감사합니다.