[Paper Review] LLaVA-PruMerge: Adaptive Token Reduction for Efficient Large Multimodal Models

논문 정보
- 제목: LLaVA-PruMerge: Adaptive Token Reduction for Efficient Large Multimodal Models
- 저자: Yuzhang Shang, Mu Cai, Bingxin Xu, Yong Jae Lee, Yan Yan
- 소속: Illinois Institute of Technology, University of Wisconsin–Madison
- 발표: ICCV 2025 (arXiv: 2024년 3월)
- 논문 링크: https://arxiv.org/abs/2403.15388
- GitHub: https://github.com/42Shawn/LLaVA-PruMerge
- Project Page: https://llava-prumerge.github.io
-
Introduction: LMM 효율성의 새로운 패러다임
1.1 Large Multimodal Models (LMMs)의 등장
- Large Language Models (LLMs)은 GPT-4, LLaMA, Mistral 등에서 보듯 강력한 추론 능력을 보여주고 있습니다. 이러한 LLM은 대규모 텍스트 코퍼스로 사전학습된 고용량 Transformer 아키텍처입니다.
- Large Multimodal Models (LMMs)은 LLM의 텍스트 생성 능력을 계승하면서, CLIP-ViT 같은 Vision Encoder를 추가하여 이미지 패치를 visual tokens으로 변환합니다. 이 visual tokens은 LLM의 prefix context로 입력되어 시각적 추론을 가능하게 합니다.
1
2
[Vision Encoder] → Visual Tokens (prefix) → [LLM] → 텍스트 응답
(CLIP-ViT) (576개) (Vicuna/LLaMA)
1.2 LMM의 계산 비용 문제
LMM은 추론(inference)에 상당한 계산 비용이 필요합니다.
이 비용의 구조를 분석하면:
| 구성요소 | 파라미터 수 | 비고 |
|---|---|---|
| Vision Encoder (ViT-L) | ~0.3B | 상대적으로 작음 |
| LLM (LLaMA/Vicuna) | 7B~13B | 주요 비용 원인 |
🔎 핵심 통찰: Vision Encoder는 LLM에 비해 매우 작으므로, LLM의 추론 비용을 줄이는 것이 전체 LMM 효율화의 핵심입니다.
1.3 기존 접근법과 한계
이전 연구들은 이러한 LLM 비용을 줄이기 위해 아래와 같은 시도들을 수행하였습니다.
| 접근법 | 방법 | 한계 |
|---|---|---|
| Small LLM 사용 | Phi-2 기반 MobileVLM, TinyGPT-V | LLM 추론 능력 희생, VQAv2/MMBench에서 큰 성능 격차 |
| Quantization | 4-bit, 8-bit 압축 | 파라미터 수는 줄지만 다른 문제 미해결 |
1.4 간과된 비용 원천: Input Context Length
하지만, 위 연구들에서 간과한 내용으로 “LLM의 비용은 파라미터 수뿐만 아니라 입력 컨텍스트 길이에서도 발생한다.”라는 사실을 지적합니다.
LLM = Transformer 아키텍처:
LLM은 Transformer 기반이며, 핵심 연산인 Self-Attention은 입력된 모든 토큰 쌍 간의 관계를 계산합니다.
Attention(Q,K,V)=softmax(QKTdk)⋅V\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right) \cdot VAttention(Q,K,V)=softmax(dkQKT)⋅V
여기서 QKTQK^TQKT 연산은 N × N 어텐션 매트릭스를 생성합니다 (N = 입력 토큰 수). 따라서 Self-Attention의 계산 복잡도는 입력 길이에 대해 O(N²)입니다.
LMM에서의 문제:
- LMM은 고정된 대량의 visual tokens을 prefix로 사용
- LLaVA-1.5: 576 visual tokens
- Video-LLaVA: 2,048+ tokens (고해상도/비디오 처리 시)
- 위와 같은 구조로 인하여 Visual tokens 수가 늘어날수록 LLM의 어텐션 연산량이 제곱으로 증가
🔎 핵심 질문: Prefix visual tokens의 수를 줄이면서도 성능을 유지할 수 있는가?
1.5 핵심 관찰: Visual Tokens의 Redundancy
본 연구에서 발견한 중요한 현상:
관찰 1: Sparse Attention Distribution
Vision Encoder의 self-attention에서 [CLS] 토큰과 spatial patches 간의 어텐션이 sparse합니다. 이는 소수의 visual tokens만이 핵심 시각 정보와 연관됨을 의미합니다.
관찰 2: 대부분의 Visual Tokens은 Redundant
기존 연구(Bolya et al., 2023; Liu et al., 2022)와 일관되게, 대부분의 visual tokens은 성능 저하 없이 제거(prune)될 수 있습니다.
1.6 제안 방법: PruMerge 개요
이러한 sparse similarity를 활용하여 중요한 visual tokens을 적응적으로 선택하는 방법을 제안합니다.
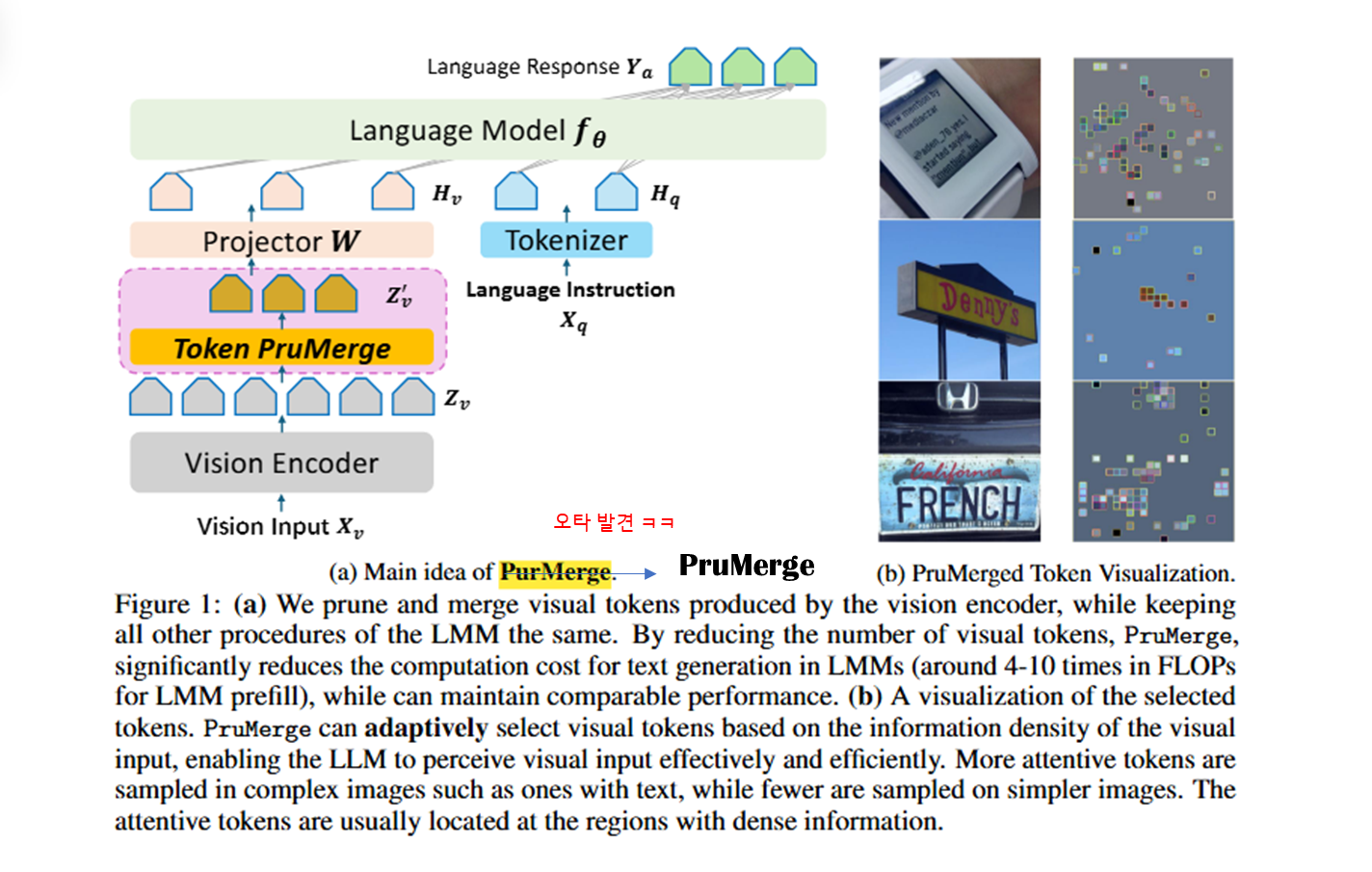
PruMerge의 핵심 아이디어:
-
Adaptive Token Selection (Prune)
- Interquartile Range (IQR) 기반 outlier detection
- [CLS] 어텐션 값이 높은 토큰을 중요 토큰으로 선별
-
Token Merging (Merge)
- IQR로 32개 토큰만 선택하면, 나머지 544개 토큰의 정보가 완전히 손실될 수 있음
- 이를 방지하기 위해 k-nearest neighbor 기반 클러스터링
- 선택된 토큰을 weighted averaging으로 업데이트
- 제거된 토큰의 정보를 보존을 목적으로 함
-
PruMerge+ (확장)
- 너무 공격적인 압축으로 인한 성능 저하 가능성 존재
- Spatial-uniform sampling 추가
- 더 포괄적이고 대표성 있는 토큰 선택 보장
📷 본 논문의 기여점
- Visual token redundancy 분석: [CLS]-spatial attention의 sparsity 관찰
- PruMerge 제안: 적응적 토큰 선택 및 병합 전략
- Plug-and-play 적용: 기존 LMM에 추가 학습 없이 적용 가능
- 다양한 모달리티 확장: 이미지뿐 아니라 비디오(Video-LLaVA)에도 적용 가능
2.1 Efficient Large Multimodal Models
1. Compact Architecture (작은 모델 사용)
MobileVLM / MobileVLM-v2
목표: 모바일 디바이스에서 실행 가능한 LMM
1
2
3
4
일반 LMM: Vision Encoder → [Vicuna-7B] → 응답
MobileVLM: Vision Encoder → [MobileLLaMA-1.4B] → 응답
↑
5배 작은 LLM
특징:
- 모바일 최적화 LLM backbone 사용
- 경량화된 projector 설계
TinyGPT-V
목표: 작은 LLM으로도 좋은 성능 달성
1
2
3
4
기존 LLaVA: Vision Encoder → [Vicuna-7B] → 응답
TinyGPT-V: Vision Encoder → [Phi-2 (2.7B)] → 응답
↑
Microsoft의 소형 LLM
특징:
- Phi-2의 강력한 reasoning 능력 활용
- 7B 대비 약 3배 작은 모델
LLaVA-Phi
목표: Phi 기반 효율적 LMM
1
Vision Encoder → [Phi-2] → 응답
특징:
- 작은 backbone + 향상된 vocabulary
- 더 나은 일반화 성능 추구
TinyLLaVA
목표: 아키텍처 선택과 학습 최적화 연구
탐구 내용:
- 어떤 Vision Encoder가 최적인가?
- 어떤 Projector가 최적인가?
- 어떤 학습 전략이 최적인가?
결론: 작은 모델도 최적화하면 큰 모델과 유사한 성능 가능
MoE-LLaVA
목표: Mixture of Experts로 효율성 향상
1
2
3
4
5
일반 LLM: 모든 파라미터가 항상 활성화
MoE-LLM: Expert 1 Expert 2 Expert 3 Expert 4
↑ ↑
Router가 선택한 Expert만 활성화 (sparse)
특징:
- 전체 파라미터는 많지만, 추론 시 일부만 사용
- 계산량 감소 + 성능 유지
2. Quantization & Compression
4/8-bit Quantization
목표: 파라미터 정밀도를 낮춰 메모리/연산 절약
1
2
3
4
5
6
7
8
기존 (FP16):
W = [0.1234, -0.5678, 0.9012, ...] ← 각 숫자가 16 bits
INT8 Quantization:
W = [0.12, -0.57, 0.90, ...] ← 각 숫자가 8 bits로 근사
INT4 Quantization:
W = [0.1, -0.6, 0.9, ...] ← 각 숫자가 4 bits로 근사
한계:
- 압축 대상: 모델의 파라미터 (weights)
- 토큰 수는 그대로 → attention 연산량 동일
3. Vision-Language Connectors
Vision Encoder 출력을 LLM 입력으로 변환하는 모듈들입니다.
MLP Projector (LLaVA)
1
Visual Token (1024-dim) → [Linear → GELU → Linear] → LLM Token (4096-dim)
특징:
- 가장 단순한 구조
- 토큰 수 변화 없음 (576 → 576)
Q-Former (BLIP-2)
1
2
3
4
5
Visual Tokens (576개)
↓
[Q-Former] ← Learnable Query Tokens (32개)와 cross-attention
↓
Query Outputs (32개)
특징:
- Learnable query가 visual 정보를 “질의”
- 토큰 수 감소 (576 → 32)
- 하지만 고정된 수의 query 사용 (adaptive 아님)
Resampler (Flamingo)
1
2
3
4
5
Visual Tokens (가변)
↓
[Perceiver Resampler] ← Latent Tokens와 cross-attention
↓
Fixed-size Output (64개)
특징:
- 다양한 해상도 입력 처리 가능
- 고정된 수의 출력 토큰
Connector 비교
| Connector | 입력 토큰 | 출력 토큰 | Adaptive? |
|---|---|---|---|
| MLP (LLaVA) | 576 | 576 | ✗ |
| Q-Former (BLIP-2) | 576 | 32 | ✗ (고정) |
| Resampler (Flamingo) | 가변 | 64 | ✗ (고정) |
| PruMerge | 576 | 약 32(유동적) | ✓ (적응적) |
2.2 Token Reduction Methods
Sparse Attention
Linformer
- 문제: Self-attention의 O(N²) 복잡도
- 해결: Key, Value를 저차원으로 projection
1
2
3
4
5
6
7
기존 Attention:
Q (N×d) @ K^T (d×N) = N×N 행렬 → O(N²)
Linformer:
K' = E @ K (k×d, where k << N)
V' = F @ V (k×d)
Q @ K'^T = N×k 행렬 → O(N×k) ≈ O(N)
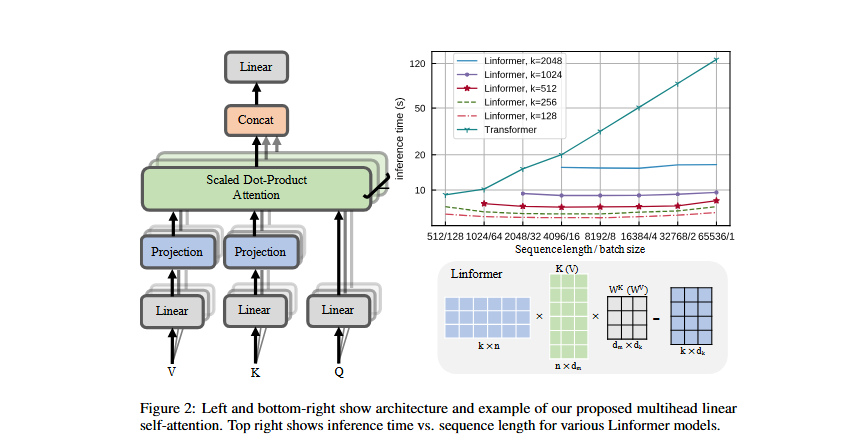
한계: LMM에 직접 적용 어려움 (prefix 구조)
ReFormer (Reformer)
- 문제: 긴 시퀀스의 attention 비용
- 해결: Locality-Sensitive Hashing (LSH) 사용
1
2
3
4
5
기존: 모든 토큰 쌍의 attention 계산
ReFormer:
1. LSH로 유사한 토큰끼리 bucket 분류
2. 같은 bucket 내에서만 attention 계산
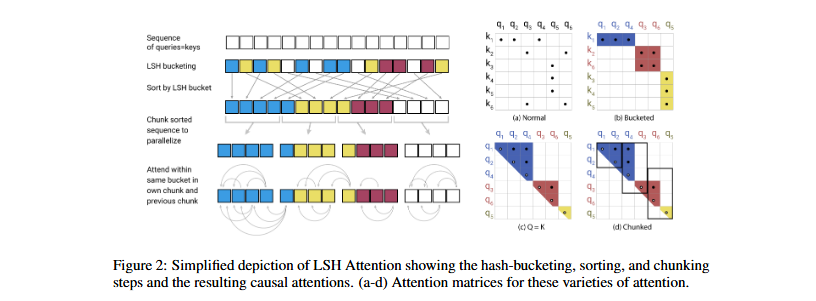
1
2
3
4
[토큰들] → [LSH Hashing] → [Bucket 1] [Bucket 2] [Bucket 3]
↓ ↓ ↓
Attention Attention Attention
(내부만) (내부만) (내부만)
한계: 여전히 모든 토큰 유지, 연산 방식만 변경
Token Merging
ToMe (Bolya et al., 2023)
- 목표: ViT 내부에서 점진적으로 토큰 수 감소
- 방법: Bipartite Matching으로 유사한 토큰 병합
1
2
3
4
5
6
7
8
ViT Block 1: 576 tokens
↓ (merge)
ViT Block 2: 500 tokens
↓ (merge)
ViT Block 3: 450 tokens
↓ (merge)
...
최종: 1 token (class token)
Bipartite Matching:
1
2
3
4
5
6
7
8
9
토큰들을 두 그룹으로 분할:
Group A: [T1, T3, T5, ...]
Group B: [T2, T4, T6, ...]
유사한 쌍 매칭 후 병합:
T1 + T2 → T'1
T3 + T4 → T'2
...
기존 Token Reduction vs PruMerge 비교
| 항목 | ToMe (기존) | PruMerge |
|---|---|---|
| 적용 위치 | ViT 내부 (layer-by-layer) | ViT 출력 후 (한 번에) |
| 목표 | ViT 연산 가속 | LLM 연산 가속 |
| 출력 | Single [CLS] token | Multiple visual tokens |
| 감소 방식 | 점진적 (576→500→450→…) | 한 번에 (576→32) |
| Adaptive | ✗ (고정 비율) | ✓ (이미지별 다름) |
-
Method: Token Pru-Merging
3.1 Preliminaries
Vision Transformers (ViTs)
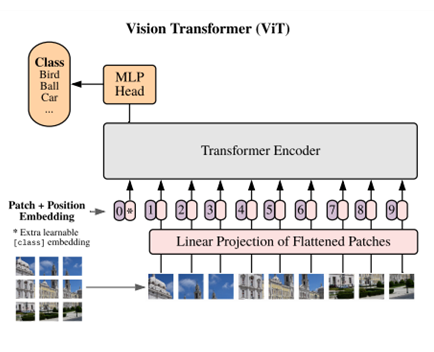
구조:
1
2
3
4
5
6
7
8
9
10
11
12
Input Image
↓ (Patch embedding)
Patch Tokens (576 tokens for 336×336 image with 14×14 patches)
+ Class Token ([CLS])
↓
Transformer Blocks (×24 for ViT-L/14)
├─ Multi-head Self-Attention (MSA)
├─ Feed-Forward Network (FFN)
├─ Skip connections
└─ Layer Normalization
↓
Output Tokens
Self-Attention 메커니즘:
1
2
3
4
5
6
7
8
# Query, Key, Value 계산
Q = X · Wq
K = X · Wk
V = X · Wv
# Attention 계산
A = softmax(Q · K^T / √dk)
Y = A · V
Class Token Attention:
1
2
# [CLS] token과 visual tokens 간의 attention
a_cls = softmax(q_cls · K^T / √dk)
핵심 관찰:
a_cls의 분포가 매우 sparse- 소수의 visual tokens만 높은 attention 값
- 대부분의 tokens는 near-zero attention
Large Multimodal Models (LMMs)
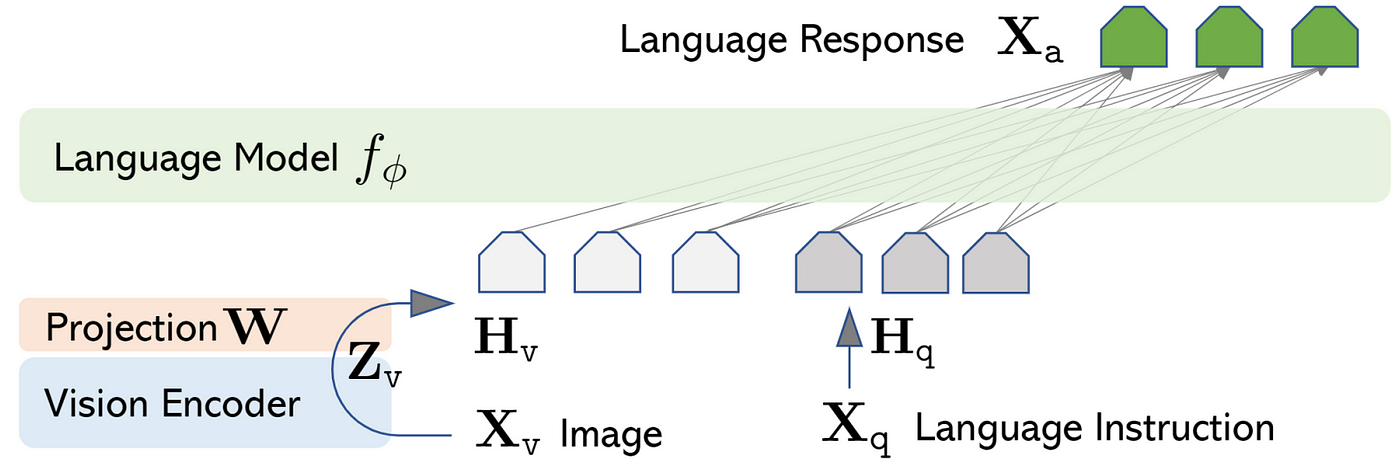
Pipeline:
1
2
3
4
5
Image X_v → [Vision Encoder] → Z_v → [Projector W] → H_v
↓
Text X_q → [Tokenizer] ──────────────────────────→ H_q
↓
[LLM f_θ] → Response Y_a
Computational Cost:
- N tokens → N × N attention matrix
- Quadratic complexity: O(N²)
- Visual tokens가 많을수록 비용 급증
💼 LLaVa PruMerge 목표: Visual tokens 수를 줄여 LLM의 computational cost 감소
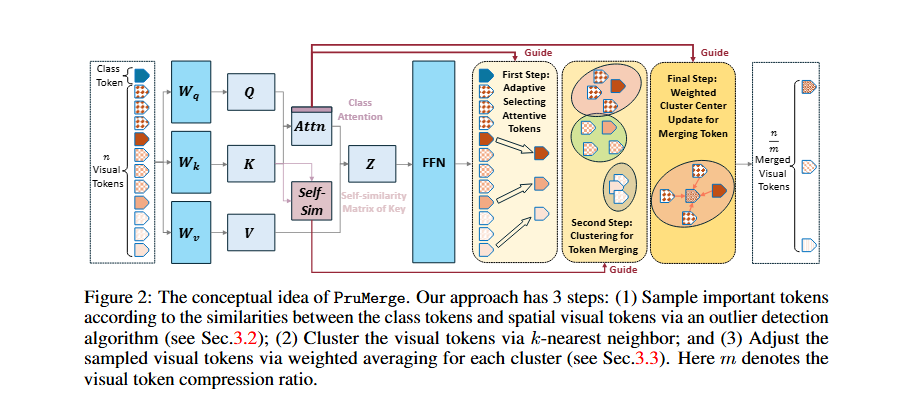
3.2 Adaptive Important Token Selection via Outlier Detection
핵심 질문: “각 visual token의 중요도를 어떻게 판단하는가?”
두 가지 극단적 패러다임
| 패러다임 | 토큰 수 | 특징 |
|---|---|---|
| LMM | 576개 (전부 사용) | 상세한 시각 정보 표현 |
| CLIP | 1개 ([CLS]만 사용) | 가장 압축된 정보 표현 |
균형점 탐색: [CLS]-Visual Attention 조사
이 두 극단의 균형점을 찾기 위해, [CLS] token과 visual tokens 간의 attention을 조사합니다.
관찰 결과 (Figure 3a):
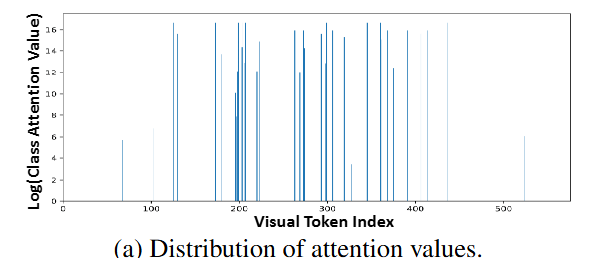
- Y축: Log(Class Attention Value)
- X축: Visual Token Index (0-575)
분포 특성:
- 대부분의 tokens: near-zero attention
- 소수의 tokens: 매우 높은 attention (outliers)
핵심 발견: Attention 분포가 매우 sparse함
→ 소수의 visual tokens만 핵심 시각 정보와 연관됨
관찰 결과 (Figure 3b):

PruMerge: 정보가 중요한 곳만 선택 → 효율적이지만 일부 정보 손실 가능PruMerge+: 중요한 곳 + 균등 샘플링 → 약간의 토큰 증가로 커버리지 보장
IQR (Interquartile Range) 기반 Outlier Detection
Sparse한 attention 분포에서 outlier = 중요한 토큰으로 판단합니다.
알고리즘:
1
2
3
4
5
6
7
8
9
10
11
12
# 1. Attention 값의 quartiles 계산
Q1 = percentile(a_cls, 25) # 1사분위수
Q3 = percentile(a_cls, 75) # 3사분위수
# 2. IQR 계산
IQR = Q3 - Q1
# 3. Upper fence (threshold) 계산
upper_fence = Q3 + 1.5 * IQR
# 4. Outliers = Important tokens
important_indices = where(a_cls > upper_fence)
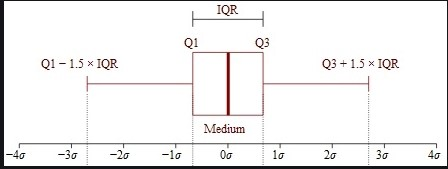
왜 IQR인가?
- Attention score는 양수이므로 upper fence만 사용
- 각 이미지의 분포에 따라 threshold가 자동 조절
- 통계적으로 검증된 robust한 outlier detection
Adaptive Selection의 특성
이미지 복잡도에 따른 자동 조절:
| 이미지 유형 | 특성 | 선택 토큰 수 |
|---|---|---|
| 복잡한 이미지 (텍스트 多) | Attention outlier 多 | 많음 (40-50개) |
| 단순한 이미지 (하늘+간판) | Attention outlier 少 | 적음 (10-20개) |

벤치마크별 평균 토큰 수 (Table 4):
비교 대상 (동일한 토큰 수에서):
| 방법 | 설명 |
|---|---|
| LLaVA-PruMerge | IQR 기반 adaptive selection |
| Sequential | 앞에서부터 순차적으로 N개 선택 |
| Spatial | 공간적으로 균등하게 N개 선택 (예: 5×8, 8×5) |
1
2
3
4
5
6
7
8
9
10
Sequential 선택:
[T1, T2, T3, ..., T40] ← 앞쪽 40개만 선택
이미지 패치 순서:
┌──────────────────────────┐
│ T1 T2 T3 ... T24 │ ← 상단만 선택됨
│ T25 T26 T27 ... T48 │
│ ... │ ← 하단은 완전 무시
│ T553 ... T576 │
└──────────────────────────┘
1
2
3
4
5
6
7
8
Spatial 선택 (5×8 = 40):
┌──────────────────────────┐
│ ■ · · · ■ · · · │
│ · · · · · · · · │
│ ■ · · · ■ · · · │
│ · · · · · · · · │
│ ■ · · · ■ · · · │
└──────────────────────────┘
1
2
3
4
5
6
7
8
PruMerge 선택:
┌──────────────────────────┐
│ · · ■ ■ ■ · · · │
│ · · ■ ■ ■ · · · │ ← 텍스트/객체 영역에 집중
│ · · ■ ■ ■ · · · │
│ · · · · · · · · │
│ · · · · · · · · │
└──────────────────────────┘
Task: TextVQA (40 tokens)
| Approach | Performance |
|---|---|
| LLaVA-PruMerge | 54.00 |
| Sequential | 42.72 |
| Spatial (5×8) | 46.85 |
| Spatial (8×5) | 47.42 |
Task: MME (40 tokens)
| Approach | Performance |
|---|---|
| LLaVA-PruMerge | 1250.07 |
| Sequential | 703.60 |
| Spatial (5×8) | 1180.23 |
| Spatial (8×5) | 1142.32 |
Task: POPE (35 tokens)
| Approach | Performance |
|---|---|
| LLaVA-PruMerge | 76.2 |
| Sequential | 11.7 |
| Spatial (5×7) | 69.8 |
| Spatial (7×5) | 71.1 |
Task: ScienceQA (16 tokens)
| Approach | Performance |
|---|---|
| LLaVA-PruMerge | 68.07 |
| Sequential | 64.20 |
| Spatial (4×4) | 66.29 |
Penultimate Layer 사용
왜 마지막 layer가 아닌 penultimate (끝에서 두 번째) layer?
- 마지막 layer: Classification에 특화
- Penultimate layer: 더 rich한 feature representation 보유
3.3 Token Supplement via Similar Key Clustering
“While pruned tokens may initially seem extraneous, they hold potential value for the perception capabilities of the LLM backbone.”
문제: Pruned Tokens의 정보 손실
Pruned tokens를 완전히 버리면:
- 큰 객체가 scene을 지배하는 경우 정보 손실
- 모델의 representation 능력 저하 가능
예시: 큰 객체가 화면을 지배하는 경우
1
2
3
4
5
6
7
┌─────────────────────────────────────┐
│ 🐘 🐘 🐘 🐘 🐘 🐘 🐘 🐘 🐘 🐘 │
│ 🐘 🐘 🐘 🐘 🐘 🐘 🐘 🐘 🐘 🐘 │
│ 🐘 🐘 🐘 🐘 🐘 🐘 🐘 🐘 🐘 🐘 │ ← 코끼리가 이미지 대부분 차지
│ 🐘 🐘 🐘 🐘 🐘 🐘 🐘 🐘 🐘 🐘 │
│ 🌿 🌿 🌿 🌿 🌿 🌿 🌿 🌿 🌿 🌿 │
└─────────────────────────────────────┘
IQR Outlier Selection 결과:
- 코끼리의 눈, 귀 등 특징적인 부분만 선택 (5-10개)
- 나머지 코끼리 몸통 부분은 pruned됨
문제: 코끼리 전체를 표현하기에 정보 부족
해결책: Pruned tokens를 버리지 않고 선택된 토큰에 병합(merge)해주면, 그 특징을 살려줄 수 있지 않을까?
Token Similarity 측정: Key Vector 활용
“Since the key vector of each patch token already contains information summarized in the self-attention module, the final layer’s key vector serves as the representation.”
왜 Key vector인가?
- Self-attention에서 key vector는 이미 해당 토큰의 정보를 요약
- 별도 계산 없이 재사용 가능
Similarity 계산:
Sim(yi,yj)=ki⋅kjT\text{Sim}(y_i, y_j) = \mathbf{k}_i \cdot \mathbf{k}_j^TSim(yi,yj)=ki⋅kjT
전체 토큰에 대해 벡터화: KKT\mathbf{K}\mathbf{K}^TKKT
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Similarity Matrix (576 × 576):
# K: 모든 토큰의 Key vectors [576, d_k]
# d_k: key dimension (예: 64)
T0 T1 T2 T3 ... T575
┌────────────────────────────────────────────┐
T0 │ 1.0 0.3 0.1 0.8 ... 0.2 │
T1 │ 0.3 1.0 0.7 0.2 ... 0.4 │
T2 │ 0.1 0.7 1.0 0.1 ... 0.3 │
T3 │ 0.8 0.2 0.1 1.0 ... 0.5 │
... │ ... ... ... ... ... ... │
T575 │ 0.2 0.4 0.3 0.5 ... 1.0 │
└────────────────────────────────────────────┘
similarity_matrix[i][j] = token i와 token j의 유사도
K-Nearest Neighbor Clustering & Weighted Merge
과정:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
def token_merge(K, Y, a_cls, unpruned_indices, k=32):
"""
K: Key vectors [576, d_k]
Y: Token features [576, d]
a_cls: Class attention [576]
unpruned_indices: IQR로 선택된 인덱스 [m]
k: neighbors 수
"""
# Step 1: 유사도 행렬 계산
similarity_matrix = K @ K.T # [576, 576]
# Step 2: 각 center에 대해 merge
merged_tokens = []
for p in unpruned_indices:
# 유사도 기반 k-nearest neighbors
sims = similarity_matrix[p] # [576]
neighbor_idx = argsort(sims)[-k:] # top-k indices
# Class attention 가중치
weights = a_cls[neighbor_idx] # [k]
# Weighted sum
merged = (weights @ Y[neighbor_idx]) / weights.sum()
merged_tokens.append(merged)
return stack(merged_tokens) # [m, d]
핵심:
- 선택된 토큰 = Cluster center
- Pruned tokens = 가장 유사한 center에 병합
- Class attention을 가중치로 사용 → 중요한 정보 더 많이 반영
(개인의견) 코드 구현체에서는 k를 32로 고정해두는데, 이를 dynamic하게 바꾸는게 더 맞지 않을까? 🤔 (링크)
1
2
3
4
5
6
7
# 1. Cosine Similarity 계산 (KK^T 대신 normalized dot product)
cos_sim_matrix = torch.bmm(key_others_norm, rest_Keys.transpose(1, 2))
## bmm : Batch 단위로 행렬 곱셈을 수행하는 함수
# 2. Top-k Nearest Neighbors 선택 ← 이게 KNN!
_, cluster_indices = torch.topk(cos_sim_matrix, k=int(32), dim=2, largest=True)
## topk: Tensor에서 가장 큰 (또는 작은) k개의 값과 인덱스를 반환
3.4 PruMerge+: Bridging the Efficiency-Performance Gap
문제: PruMerge의 성능 격차
PruMerge는 ~14배 압축 (5.5% tokens)을 달성하지만:
- 원본 LLaVA 대비 marginal performance drop 발생
- 특정 영역에 토큰이 편중될 수 있음
해결책: Spatial Uniform Sampling 추가
PruMerge+ 전략:
1
Final Tokens = Attention-based Outliers + Spatially-uniform Samples
알고리즘:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# Step 1: IQR로 outlier ratio 계산
if if_adaptive:
reduction_ratio = outlier_dectection(cls_attn) # 예: 0.05 (5%)
# Step 2: Top-k로 outlier 선택
_, idx = torch.topk(cls_attn, int(N * reduction_ratio), dim=1, largest=True)
# idx: [B, ~32] ← IQR 기반 선택된 인덱스
# Step 3: Spatial Uniform Sampling
if if_adaptive:
step_length = int(1 / reduction_ratio) # 예: 1/0.05 = 20
# 균등 간격으로 샘플링 (step_length/3 간격)
arithmetic_sequence = torch.arange(0, 575, int(step_length / 3))
# 예: step=20 → step/3≈6 → [0, 6, 12, 18, 24, ..., 570]
# 이미 선택된 인덱스 제외 (중복 제거)
original_tensor_1d = idx.flatten()
filtered_sequence = [x for x in arithmetic_sequence if x not in original_tensor_1d]
# Step 4: Union (합집합)
concatenated_tensor = torch.cat((idx, filtered_sequence.unsqueeze(0)), dim=1)
idx = concatenated_tensor # 최종 인덱스
효과:
- 공간적으로 underrepresented 영역 보완
- 더 comprehensive한 visual representation
PruMerge vs PruMerge+ 비교
| 항목 | PruMerge | PruMerge+ |
|---|---|---|
| 압축률 | ~14× (5.5%) | ~4× (25%) |
| 선택 방식 | IQR Outlier만 | Outlier + Spatial Uniform |
| 공간 커버리지 | 편중 가능 | 균등 보장 |
성능 비교 (Vicuna-7B):
| Metric | LLaVA-1.5 | PruMerge | PruMerge+ |
|---|---|---|---|
| VQAv2 | 78.5 | 72.0 | 76.8 |
| ScienceQA | 66.8 | 68.5 | 68.3 |
| TextVQA | 58.2 | 56.0 | 57.1 |
| POPE | 85.9 | 76.3 | 84.0 |
| MME | 1510.7 | 1350.3 | 1462.4 |
| MMBench | 64.3 | 60.9 | 64.9 |
Trade-off:
- PruMerge: 최대 효율성 (14× 압축), 약간의 성능 저하
- PruMerge+: 효율성 + 성능 균형 (4× 압축, 거의 원본 성능)
3.5 Algorithm Summary
Algorithm 1: Token PruMerge and PruMerge+
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
# Input: K, Q (penultimate layer), Y (output tokens), n (token count)
# Output: Y' (m tokens, m << n)
def token_prumerge(K, Q, Y, n):
# Step 1: Calculate class attention
a_cls = calculate_attention(Q_cls, K) # Eq 3.2
# Step 2: Adaptive token selection via IQR
indices = IQR_outlier_detection(a_cls) # Sec 3.2
m = len(indices)
selected_indices = indices
# Step 3 (Optional - PruMerge+): Spatial sampling
if PRUMERGE_PLUS:
r_o = m / n
spatial_indices = spatial_uniform_sample(r_o)
selected_indices = indices + spatial_indices
m = len(selected_indices)
# Step 4: Token merging via k-NN clustering
Y_prime = []
for p in selected_indices:
# Calculate similarity
similarities = cosine_similarity(
K[p],
K[others]
)
# Find k nearest neighbors
neighbor_indices = topk(similarities, k=32)
# Weighted averaging
weights = a_cls[neighbor_indices]
y_p_prime = weighted_average(
Y[neighbor_indices],
weights=weights
)
Y_prime.append(y_p_prime)
return Y_prime # m tokens
핵심 단계:
- AITS: IQR로 중요 토큰 선택
- (Optional) Spatial sampling
- TS: k-NN clustering + weighted merging
-
Experiments
4.1 Main Results
실험 설정
Base Model: LLaVA-1.5 (7B, 13B)
- CLIP ViT-L/14 vision encoder
- Vicuna-7B / Vicuna-13B LLM
- 336×336 resolution
- 원본: 576 visual tokens
Training:
- LoRA fine-tuning (1 epoch)
- LLaVA-1.5 instruction data 사용
- Reduced visual tokens로 학습
Evaluation Benchmarks:
- VQAv2: Visual question answering
- ScienceQA (SQAI): Multimodal reasoning
- TextVQA (VQAT): OCR-based QA
- POPE: Hallucination evaluation
- MME: Perception & cognition
- MMBench (MMB): Comprehensive evaluation
성능 비교
Table 1: 6개 벤치마크 결과
| Method | LLM | VQAv2 | SQAI | VQAT | POPE | MME | MMB |
|---|---|---|---|---|---|---|---|
| Existing Methods | |||||||
| BLIP-2 | Vicuna-13B | 41.0 | 61.0 | 42.5 | 85.3 | 1293.8 | - |
| InstructBLIP | Vicuna-13B | - | 63.1 | 50.7 | 78.9 | 1212.8 | - |
| Qwen-VL-Chat | Qwen-7B | 78.2 | 68.2 | 61.5 | - | 1487.5 | 60.6 |
| LLaVA-1.5 Baselines | |||||||
| LLaVA-1.5 | Vicuna-7B | 78.5 | 66.8 | 58.2 | 85.9 | 1510.7 | 64.3 |
| + PruMerge (5.5%) | Vicuna-7B | 72.0 | 68.5 | 56.0 | 76.3 | 1350.3 | 60.9 |
| + PruMerge+ (25%) | Vicuna-7B | 76.8 | 68.3 | 57.1 | 84.0 | 1462.4 | 64.9 |
| LLaVA-1.5 | Vicuna-13B | 80.0 | 71.6 | 61.3 | 85.9 | 1531.3 | 67.7 |
| + PruMerge (5.5%) | Vicuna-13B | 72.8 | 71.0 | 58.4 | 78.5 | 1428.2 | 62.3 |
| + PruMerge+ (25%) | Vicuna-13B | 77.8 | 71.0 | 58.6 | 84.4 | 1485.5 | 65.7 |
주요 발견:
-
PruMerge+ (25% tokens):
- VQAv2: 76.8 (원본 78.5 대비 -1.7)
- ScienceQA: 68.3 (원본 66.8 대비 +1.5)
- MME: 1462.4 (원본 1510.7 대비 -48.3)
- MMBench: 64.9 (원본 64.3 대비 +0.6)
- → Comparable performance
-
PruMerge (5.5% tokens):
- ScienceQA: 68.5 (원본 대비 +1.7)
- POPE: 76.3 (원본 85.9 대비 -9.6)
- → 일부 태스크에서 성능 향상!
-
vs. Previous Methods:
- BLIP-2, InstructBLIP 대비 훨씬 우수
- Qwen-VL-Chat과 comparable
왜 일부 태스크에서 성능 향상?
ScienceQA에서 향상 이유:
- 중요한 시각 정보에 집중
- Redundant tokens 제거로 signal-to-noise 비율 향상
- 추론에 필요한 핵심 features만 선택
POPE에서 PruMerge가 약한 이유:
- Object presence detection 필요
- Spatial coverage 중요
- Aggressive pruning (5.5%)으로 일부 객체 정보 손실
- → PruMerge+가 이 문제 해결 (84.0)
4.2 Efficiency Analysis
Computational Cost (Table 2)
실험 환경: Tesla V100 GPU
방법론: Roofline model 기반 theoretical analysis
LLaVA-1.5 (Vicuna-7B):
| Config | FLOPs (TB) | Prefill Time (ms) | Total Memory (GB) | Activation (GB) |
|---|---|---|---|---|
| FP16 | ||||
| Original | 9.3 | 88.6 | 23.3 | 4.60 |
| + PruMerge | 0.91 | 15.3 | 13.7 | 0.28 |
| Speedup | 10.2× | 5.8× | 1.7× | 16.4× |
| INT4 | ||||
| Original | 2.3 | 151.6 | 5.9 | 1.20 |
| + PruMerge | 0.28 | 14.9 | 3.5 | 0.07 |
| Speedup | 8.2× | 10.2× | 1.7× | 17.1× |
LLaVA-1.5 (Vicuna-13B):
| Config | FLOPs (TB) | Prefill Time (ms) | Total Memory (GB) | Activation (GB) |
|---|---|---|---|---|
| FP16 | ||||
| Original | 18.2 | 170.5 | 41.6 | 7.30 |
| + PruMerge | 1.80 | 29.5 | 26.6 | 0.44 |
| Speedup | 10.1× | 5.8× | 1.6× | 16.6× |
| INT4 | ||||
| Original | 4.6 | 294.9 | 10.5 | 1.80 |
| + PruMerge | 0.45 | 29.0 | 6.8 | 0.11 |
| Speedup | 10.2× | 10.2× | 1.5× | 16.4× |
핵심 효율성 향상:
-
FLOPs 감소: ~10배
- Quadratic complexity 효과: O(n²) → O(m²)
- 576² → 40² ≈ 331,776 → 1,600
-
Prefill Time: 5.8~10.2배 빨라짐
- FP16: 88.6ms → 15.3ms
- INT4: 151.6ms → 14.9ms
- INT4 + PruMerge가 가장 빠름!
-
Memory 절감:
- Total: 1.5~1.7배 감소
- Activation: 16배 이상 감소
-
Quantization과의 시너지:
- INT4 quantization 적용 시 더 빠른 속도
- Orthogonal techniques로 결합 가능
Scenario Analysis
가정:
- Image: 336×336 (576 visual tokens)
- Text prompt: 40 tokens
- PruMerge 적용 후: 40 visual tokens
Token 수 비교:
1
2
3
4
Original: 576 (visual) + 40 (text) = 616 tokens
PruMerge: 40 (visual) + 40 (text) = 80 tokens
Reduction: 616 → 80 (7.7× fewer tokens)
Attention Computation:
1
2
3
4
Original: 616² = 379,456 operations
PruMerge: 80² = 6,400 operations
Speedup: 59.3× in attention matrix computation
4.3 Generalization on Video-LLM
Video-LLaVA 통합
Video-LLaVA 특성:
- 8 frames per video clip
- 16×16 patches per frame
- 2048 visual tokens (8 × 256)
- LLaVA-1.5 대비 4배 많은 tokens
PruMerge 적용 (Training-free):
- Inference 시에만 적용
- 추가 학습 불필요
- 즉시 사용 가능
결과 (Table 3)
Video QA Benchmarks:
| Method | LLM | MSVD-QA | MSRVT-QA | ActivityNet-QA | |||
|---|---|---|---|---|---|---|---|
| Acc | Score | Acc | Score | Acc | Score | ||
| Baselines | |||||||
| FrozenBiLM | 1B | 32.2 | - | 16.8 | - | 24.7 | - |
| VideoChat | 7B | 56.3 | 2.8 | 45.0 | 2.5 | - | 2.2 |
| LLaMA-Adapter | 7B | 54.9 | 3.1 | 43.8 | 2.7 | 34.2 | 2.7 |
| Video-LLaMA | 7B | 51.6 | 2.5 | 29.6 | 1.8 | 12.4 | 1.1 |
| Video-ChatGPT | 7B | 64.9 | 3.3 | 49.3 | 2.8 | 35.2 | 2.7 |
| Video-LLaVA | |||||||
| Original | 7B | 70.7 | 3.9 | 59.2 | 3.5 | 45.3 | 3.3 |
| + PruMerge (12.5%) | 7B | 71.1 | 3.9 | 58.4 | 3.5 | 48.3 | 3.4 |
| + PruMerge+ (25%) | 7B | 71.1 | 3.9 | 59.3 | 3.6 | 47.7 | 3.4 |
놀라운 발견:
-
성능 향상:
- MSVD-QA: 70.7 → 71.1 (+0.4)
- ActivityNet-QA: 45.3 → 48.3 (+3.0)
- Token 감소했는데 성능 향상!
-
토큰 압축:
- Original: 2048 tokens
- PruMerge: 256 tokens (12.5%)
- PruMerge+: 512 tokens (25%)
- 8배 / 4배 압축
-
Training-free:
- Video 데이터로 재학습 불필요
- Inference 시에만 적용
- 즉시 사용 가능
Insight:
- Video tokens에도 significant redundancy 존재
- Temporal + spatial redundancy 모두 활용 가능
- Future direction: Temporal token reduction 탐구
4.4 Ablation Study
용어 정리
PruMerge의 두 모듈
- AITS : Adaptive Important Token Selection
- IQR로 중요 토큰 선택
- TS: Token Supplement
- KNN으로 pruned 정보 병합
4.4.1 Token Sampling Strategy Analysis (Table 4)
비교 전략:
- LLaVA-PruMerge: IQR-based adaptive sampling
- Sequential: 처음 N개 토큰 선택
- Spatial: N개 토큰을 공간적으로 균등 배치
결과 (동일한 토큰 수로 비교):
TextVQA (40 tokens):
- PruMerge: 54.00
- Sequential: 42.72
- Spatial 5×8: 46.85
- Spatial 8×5: 47.42
- → PruMerge가 11.3% 더 높음
MME (40 tokens):
- PruMerge: 1250.07
- Sequential: 703.60
- Spatial 5×8: 1180.23
- Spatial 8×5: 1142.32
- → PruMerge가 77.7% 더 높음
POPE (35 tokens):
- PruMerge: 76.2
- Sequential: 11.7 (!)
- Spatial 5×7: 69.8
- Spatial 7×5: 71.1
- Spatial 6×6: 67.9
- → PruMerge가 6.5배 높음
ScienceQA (16 tokens):
- PruMerge: 68.07
- Sequential: 64.20
- Spatial 4×4: 66.29
- → PruMerge가 3.87% 더 높음
분석:
Sequential의 문제:
- 처음 N개 토큰 = 이미지 특정 영역만
- Spatial bias 심각
- POPE에서 거의 random guess (11.7)
Spatial의 장점:
- 전체 이미지 커버리지
- 균형잡힌 representation
- Sequential보다 훨씬 우수
PruMerge의 우수성:
- Attention-guided selection
- 정보 밀도 높은 영역 집중
- Adaptive to image complexity
- 특히 TextVQA (OCR)에서 큰 차이
- 텍스트 영역에 토큰 집중
- 세밀한 정보 보존
4.4.2 Effectiveness of Each Module (Table 5)
실험 설정:
- 고정: 40 tokens (6.9%)
- Vicuna-7B 모델
- 4개 벤치마크
Module 조합:
| Method | SQAI | VQAT | POPE | MME |
|---|---|---|---|---|
| LLaVA-1.5 (baseline) | 66.8 | 58.2 | 85.9 | 1510.7 |
| w. AITS only | 66.5 | 54.8 | 75.7 | 1221.6 |
| w. AITS & TS | 68.5 | 56.0 | 76.3 | 1350.3 |
분석:
AITS (Adaptive Important Token Selection) 단독:
- SQA: 66.5 (baseline 66.8)
- TextVQA: 54.8 (baseline 58.2)
- POPE: 75.7 (baseline 85.9)
- MME: 1221.6 (baseline 1510.7)
- → 토큰 선택만으로는 성능 저하
AITS + TS (Token Supplement):
- SQA: 68.5 (baseline 대비 +1.7)
- TextVQA: 56.0 (baseline 대비 -2.2)
- POPE: 76.3 (baseline 대비 -9.6)
- MME: 1350.3 (baseline 대비 -160.4)
- → Token merging이 필수적!
TS의 효과:
- SQA: +2.0 (66.5 → 68.5)
- TextVQA: +1.2 (54.8 → 56.0)
- POPE: +0.6 (75.7 → 76.3)
- MME: +128.7 (1221.6 → 1350.3)
- → 모든 태스크에서 개선
핵심 Insight:
- Token selection만으로는 부족
- Merging이 pruned tokens 정보 보존
- k-NN clustering + weighted averaging 효과
4.4.3 Training Analysis (Table 6)
비교:
- Training-free: PruMerge만 적용, 학습 X
- LoRA fine-tuning: PruMerge + LoRA 1 epoch
결과 (40 tokens, Vicuna-7B):
| Method | SQAI | VQAT | POPE | MME |
|---|---|---|---|---|
| LLaVA-1.5 (baseline) | 66.8 | 58.2 | 85.9 | 1510.7 |
| w.o. LoRA-FT | 68.0 | 54.0 | 76.2 | 1250.1 |
| w. LoRA-FT | 68.5 | 56.0 | 76.3 | 1350.3 |
분석:
Training-free 성능:
- SQA: 68.0 (baseline 대비 +1.2)
- TextVQA: 54.0 (baseline 대비 -4.2)
- POPE: 76.2 (baseline 대비 -9.7)
- MME: 1250.1 (baseline 대비 -260.6)
- → 일부 태스크는 즉시 사용 가능
Fine-tuning 효과:
- SQA: +0.5 (68.0 → 68.5)
- TextVQA: +2.0 (54.0 → 56.0)
- POPE: +0.1 (76.2 → 76.3)
- MME: +100.2 (1250.1 → 1350.3)
- → 모든 태스크에서 개선
Trade-off:
- Training-free: 빠른 적용, 일부 성능 저하
- Fine-tuning: 최고 성능, 추가 학습 필요 (1 epoch)
실용적 선택:
- Resource 충분: Fine-tuning 권장
- 빠른 적용 필요: Training-free로 시작
-
요약
5.1 Adaptive Token Selection
핵심 혁신:
- IQR-based outlier detection: 통계적으로 검증된 방법
- Image-specific adaptation: 이미지마다 다른 수의 토큰
- Learned importance: 모델이 학습한 attention pattern 활용
장점:
- Manual threshold 불필요
- Robust to different image types
- Computation-efficient (단순 통계 계산)
5.2 Token Merging via k-NN
핵심 혁신:
- Information preservation: Pruned tokens 정보 보존
- Similarity-based clustering: Semantic 유사도 기반
- Weighted aggregation: Attention으로 가중
장점:
- Lossless에 가까운 압축
- Semantic consistency 유지
- Large objects 정보 보존
5.3 PruMerge+ Hybrid Strategy
핵심 혁신:
- Attention + Spatial: 두 가지 원칙 결합
- Balanced coverage: 전체 이미지 커버리지
- Performance-efficiency trade-off: 선택 가능
장점:
- Minimal performance drop
- Spatial bias 방지
- Flexible deployment
5.4 Plug-and-Play Design
핵심 혁신:
- Vision encoder level: 아키텍처 독립적
- Training-free option: 즉시 사용 가능
- Modular implementation: 쉬운 통합
장점:
- LLaVA-1.5, Video-LLaVA 등 즉시 적용
- Minimal code changes
- Research-friendly
-
Limitations 및 향후 방향
현재 한계 (논문 기준)
1. Not Entirely Lossless
- Visual token compression이 완전히 lossless하지 않음
- 원본 LLaVA 대비 marginal performance gap 존재
- PruMerge+ (25%)로 대부분 해결되나 완전하지 않음
2. Large-Scale Model 검증 부족
- Academic setting의 computational resources 한계
- LLaVA-Next with Yi-34B 등 대규모 모델에 대한 검증 미완료
향후 연구 방향 (논문 기준)
1. Fully Lossless Compression
- 완전 무손실 토큰 압축 알고리즘 개발
- Performance gap 완전 제거 목표
2. Larger-Scale Models 확장
- LLaVA-Next with Yi-34B backbone 등 대규모 모델 적용
- Generalization 및 broader impact 검증
-
Conclusion
LLaVA-PruMerge는 Large Multimodal Models의 효율성을 획기적으로 개선:
핵심 기여:
- Adaptive token selection: IQR-based outlier detection
- Information-preserving merging: k-NN clustering + weighted averaging
- PruMerge+: Attention + spatial hybrid strategy
- 14배 / 4배 압축: 성능 유지하면서 대폭 압축
의의:
- Visual token 수 관점의 최초 효율화 연구
- Plug-and-play 방식으로 즉시 적용 가능
- Training-free option으로 빠른 배포
- Video-LLM에도 즉시 적용 가능
실용성:
- 10배 FLOPs 감소
- 5.8~10.2배 빠른 prefill
- 50% 메모리 절감
- Quantization과 orthogonal (결합 가능)
LLaVA-PruMerge는 효율성과 성능의 균형을 이루며, LMM의 실용적 배포를 위한 중요한 단계입니다.