[NLP] 4. Natural Language Embeddings
Natural Language Embeddings
자연어 처리(NLP)에서 텍스트 데이터를 효율적으로 다루기 위해 다양한 자연어 임베딩 기법(Natural Language Embedding)이 사용됩니다. 이번 포스트에서는 이러한 기법들을 자세히 설명하고, 각 기법의 예시를 통해 이해를 돕고자 합니다.
🔎 Text Representation Learning & Natural Language Embedding이란?
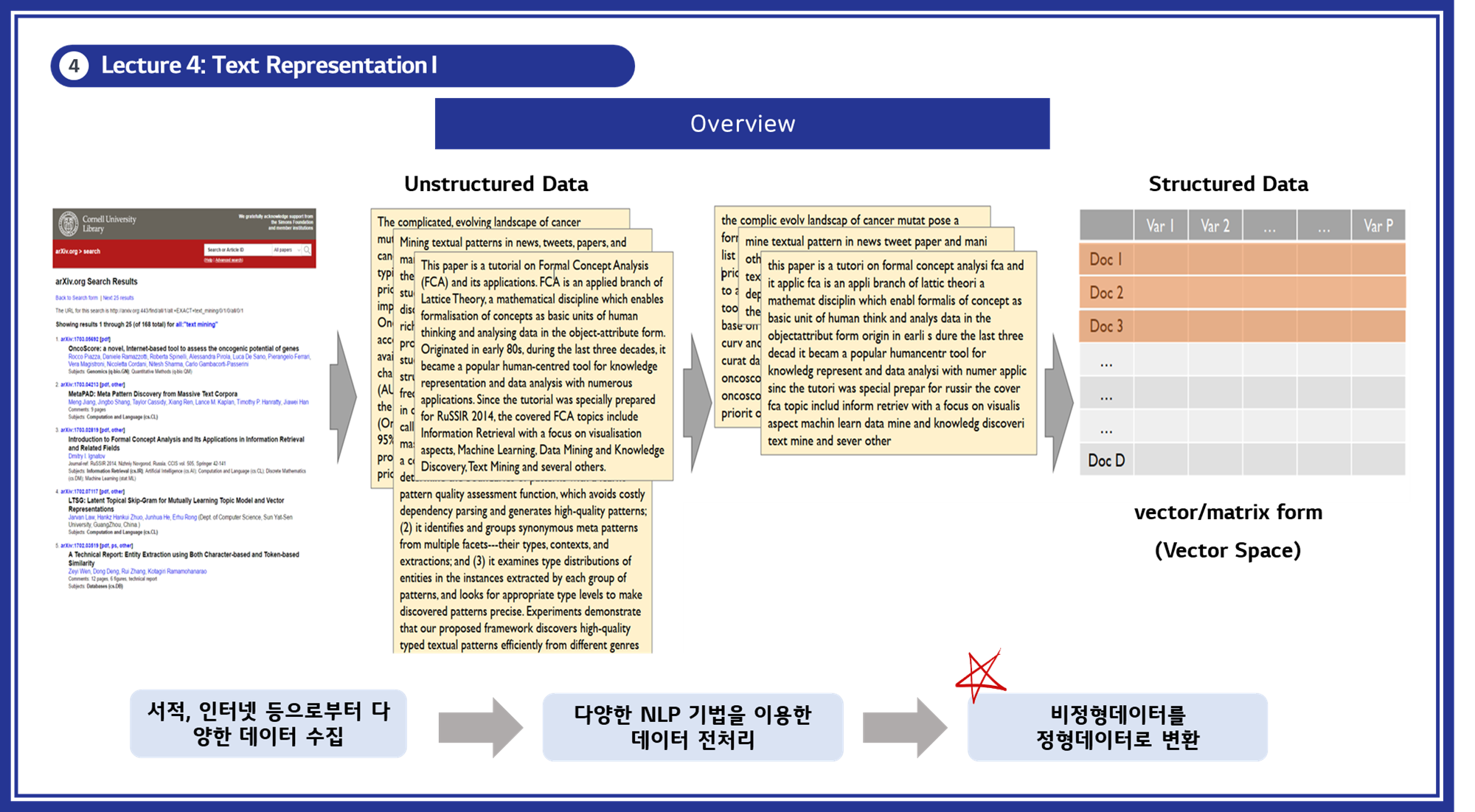
텍스트 표현 학습(Text Representation Learning)은 비정형 텍스트 데이터를 정형 데이터로 변환하여 컴퓨터가 이해하고 처리할 수 있게 만드는 과정입니다.자연어 임베딩(Natural Language Embedding)은 이러한 과정에서 텍스트 데이터를 벡터 형식으로 변환하는 다양한 기법들을 포함합니다.- 이 과정에서 중요한 것은 단어 간의 의미적 유사성과 문맥 정보를 유지하면서 데이터를 변환하는 것입니다.
-
비정형 데이터를 정형 데이터로 변환하기
- 비정형 데이터는 텍스트와 같은 비구조화된 데이터를 말하며, 이를 정형 데이터로 변환하는 것이 자연어 처리(NLP)의 첫 번째 단계입니다.
- 이 과정은 데이터를 컴퓨터가 이해할 수 있는 형태로 바꾸는 것을 목표로 합니다.
- 비정형 데이터를
벡터또는매트릭스형식으로 변환하여 정형 데이터로 만들 수 있습니다. -
주요 과정:
데이터 수집: 서적, 인터넷 등 다양한 소스로부터 데이터를 수집합니다.데이터 전처리: 수집한 데이터를 NLP 기법을 이용해 전처리합니다.- 대소문자 통일: “They”와 “they”를 모두 소문자로 통일.
- 불필요한 문장 기호 제거: 예를 들어, “!”나 “?” 같은 기호를 제거.
- 숫자 제거: 필요 없는 숫자는 제거.
- 불용어 제거: 문법 요소 등 중요한 의미를 담고 있지 않은 단어 제거.
정형 데이터로 변환: 비정형 데이터를 벡터 또는 매트릭스 형태로 변환합니다.
-
텍스트 벡터화 기법
텍스트를 벡터로 변환하는 다양한 기법을 소개합니다.
2.1 백 오브 워즈 (Bag-of-Words) 모델
Bag of Words는 단어를 벡터로 표현하는 가장 간단한 방법으로, 단어의 순서를 고려하지 않고 문서 내 단어의 빈도를 기반으로 문서를 벡터화합니다.
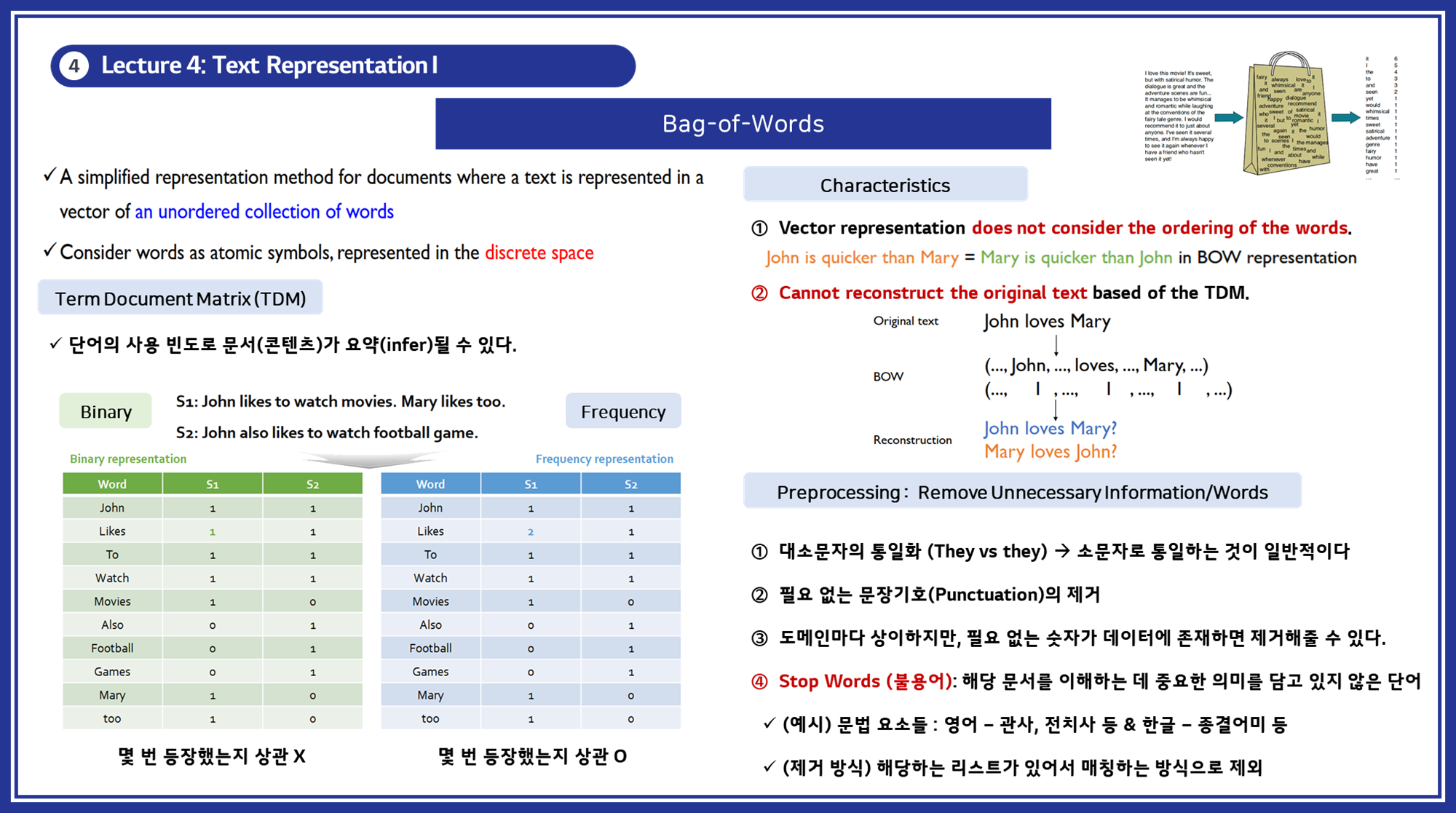
서로 다른 문서들의 BoW들을 결합하면 문서 단어 행렬(Document-Term Matrix, DTM) 또는 단어 문서 행렬(Term-Document Matrix, TDM)으로 표현할 수 있습니다. 이렇게 하면 서로 다른 문서들까지 확장해서 비교할 수 있게 됩니다.
- 개념: 단어의 등장 순서를 고려하지 않고, 문서 내 단어의 빈도를 세어 벡터를 구성합니다.
- BoW 생성 방식:
1
2
(1) 각 단어에 고유한 정수 인덱스 부여.
(2) 각 인덱스의 위치에 단어 토큰의 등장 횟수를 기록한 벡터 생성.
- 특징: 단어의 순서를 무시하며 빈도 기반으로 벡터를 구성합니다.
- 예시:
1
2
3
4
5
6
문서1: "I love machine learning."
문서2: "Machine learning is fun."
BoW 벡터:
문서1: [1, 1, 1, 1, 0, 0] # "I", "love", "machine", "learning", "is", "fun"의 순서
문서2: [0, 0, 1, 1, 1, 1]
- 예시 코드:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
from konlpy.tag import Okt
okt = Okt()
def build_bag_of_words(document):
# 온점 제거 및 형태소 분석
document = document.replace('.', '')
tokenized_document = okt.morphs(document)
word_to_index = {}
bow = []
for word in tokenized_document:
if word not in word_to_index.keys():
word_to_index[word] = len(word_to_index)
# BoW에 전부 기본값 1을 넣는다.
bow.insert(len(word_to_index) - 1, 1)
else:
# 재등장하는 단어의 인덱스
index = word_to_index.get(word)
# 재등장한 단어는 해당하는 인덱스의 위치에 1을 더한다.
bow[index] = bow[index] + 1
return word_to_index, bow
2.2 단어 가중치 (Word Weighting) - TF-IDF
특정 단어가 문서에서 얼마나 중요한지를 측정하기 위해 단어 빈도(TF, Term-Frequency)와 문서 빈도(DF, Document-Frequency)를 사용합니다.
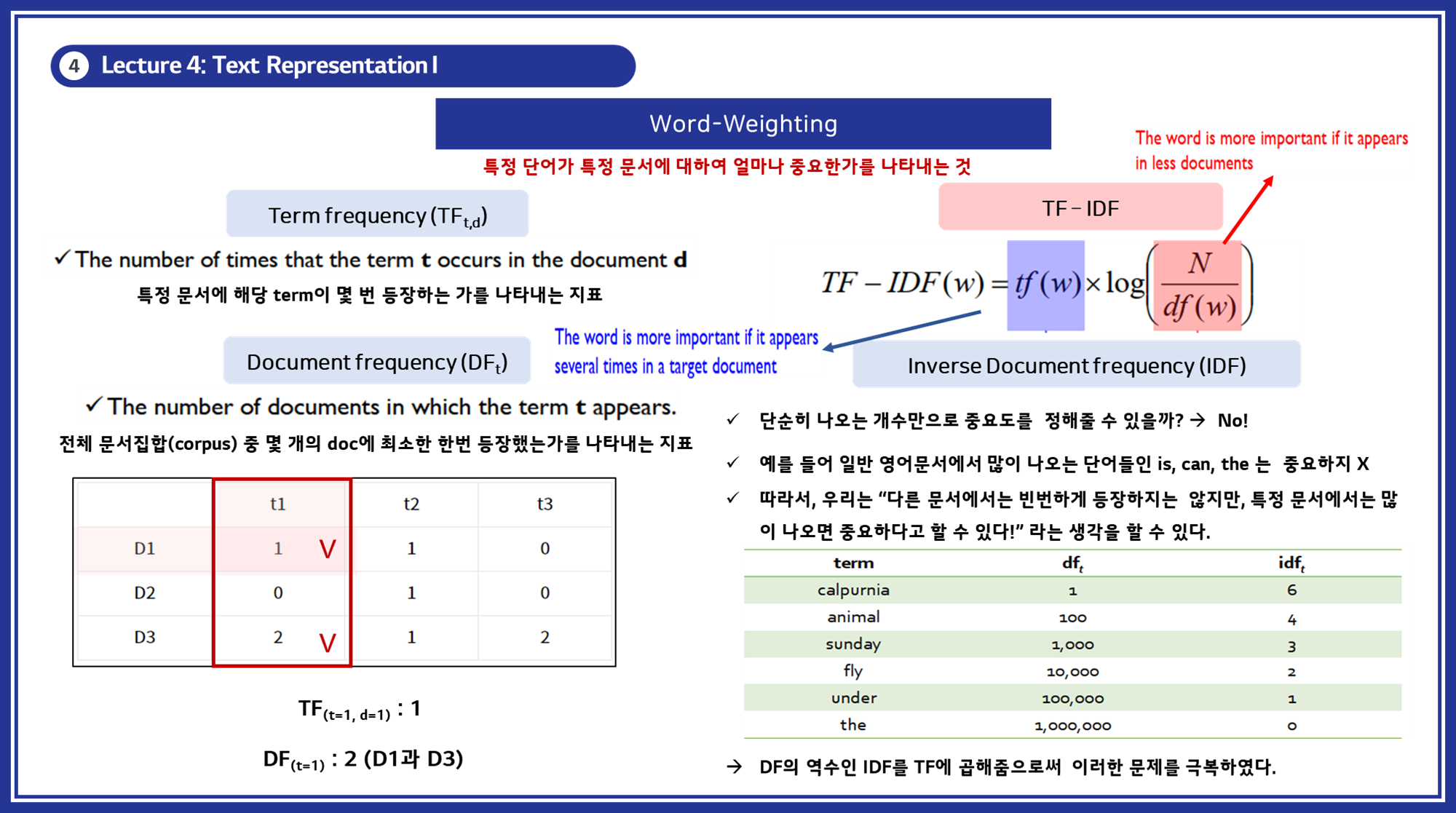
- 개념: 자주 등장하지 않는 단어가 특정 문서에서 많이 등장할 경우 해당 단어의 가중치를 높입니다.
-
TF-IDF 생성 방식:
TF (Term Frequency): tf(d,t), 특정 문서 d에서의 특정 단어 t의 등장 횟수.DF (Document Frequency): df(t), 특정 단어 t가 등장한 문서의 수.IDF (Inverse Document Frequency): idf(t), 전체 문서에서 단어가 등장한 빈도의 역수- 수식: log(n/(1+df(t)))log({n}/{(1+df(t))})log(n/(1+df(t)))
TF-IDF: TF와 IDF를 곱하여 계산.
- 특징: 단순 빈도의 단점을 보완하여 단어의 중요성을 반영합니다. (가중치 개념 추가)
-
예시:
문서1: “I love machine learning.”문서2: “Machine learning is fun.”- 단어 ‘machine’에 대해:
- n=2n = 2n=2 (전체 문서 수)
- df(t)=2\text{df}(t) = 2df(t)=2 (‘machine’이 등장하는 문서 수)
- 따라서 IDF는 다음과 같이 계산됩니다:
- IDF(machine)=log(21+2)=log(23)=log(0.6667)≈−0.176\text{IDF}(machine) = \log\left(\frac{2}{1 + 2}\right) = \log\left(\frac{2}{3}\right) = \log(0.6667) \approx -0.176IDF(machine)=log(1+22)=log(32)=log(0.6667)≈−0.176
- TF 계산
- 문서1에서 ‘machine’의 TF: 1
- 문서2에서 ‘machine’의 TF: 1
- TF-IDF 계산
- 문서1: TF-IDF(machine)=1×−0.176=−0.176\text{TF-IDF}(machine) = 1 \times -0.176 = -0.176TF-IDF(machine)=1×−0.176=−0.176
- 문서2: TF-IDF(machine)=1×−0.176=−0.176\text{TF-IDF}(machine) = 1 \times -0.176 = -0.176TF-IDF(machine)=1×−0.176=−0.176
- 예시 코드:
1
2
3
4
5
6
7
8
9
from sklearn.feature_extraction.text import TfidfVectorizer
documents = ["I love machine learning.", "Machine learning is fun."]
tfidf_vectorizer = TfidfVectorizer()
tfidf_matrix = tfidf_vectorizer.fit_transform(documents)
print(tfidf_matrix.toarray())
print(tfidf_vectorizer.get_feature_names_out())
2.3 N-Grams 모델
단어의 순서를 고려하기 위해 N-Grams 모델을 사용합니다. 이는 단어의 연속된 N개의 단어 조합을 특징으로 합니다.
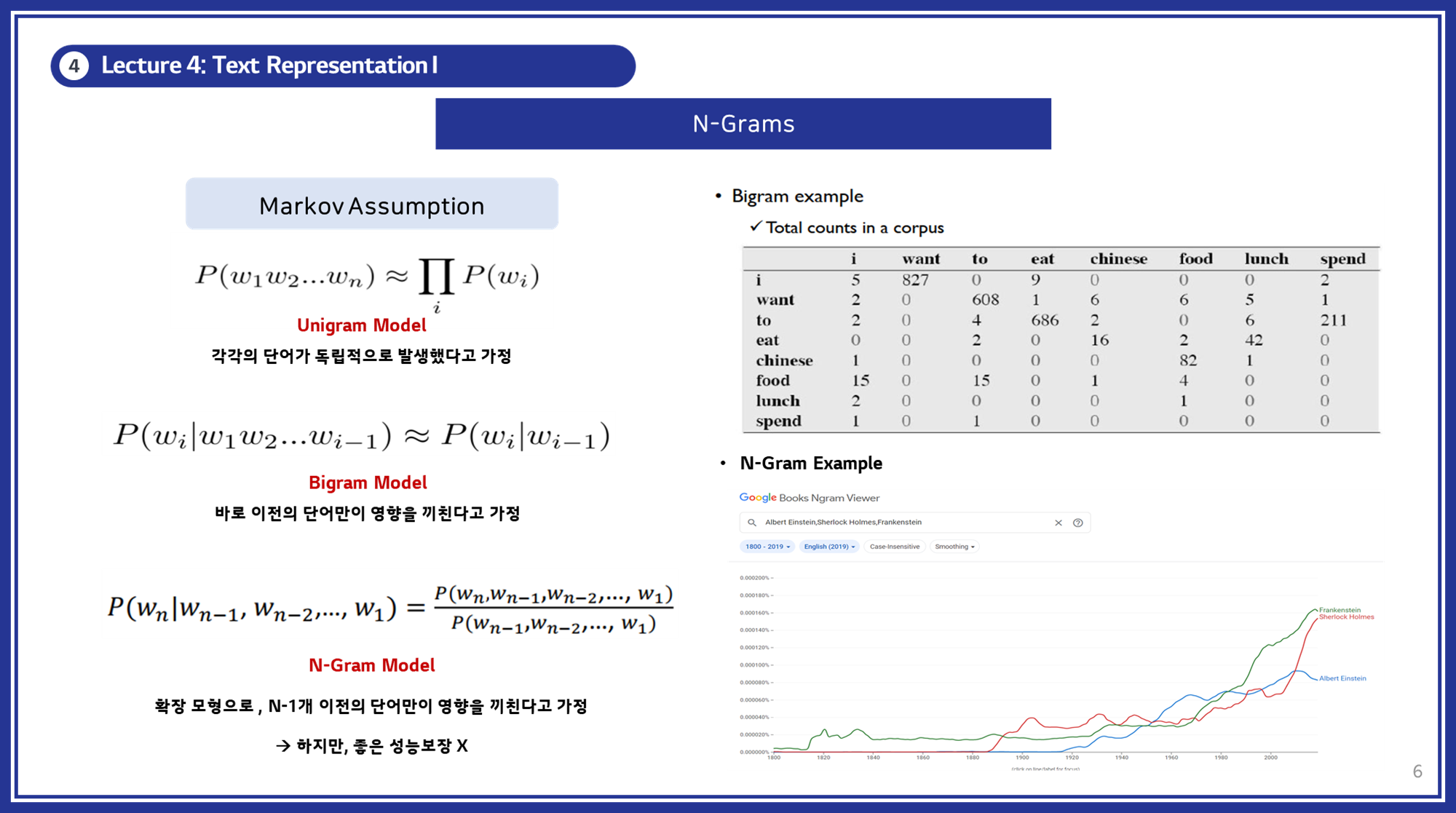
- 개념: N개의 연속된 단어를 하나의 토큰으로 취급하여 벡터를 구성합니다.
유니그램(Unigram): 단일 단어로 구성된 N-그램. (N=1)바이그램(Bigram): 두 단어로 구성된 N-그램. (N=2)트라이그램(Trigram): 세 단어로 구성된 N-그램. (N=3)4-그램(4-gram): 네 단어로 구성된 N-그램. (N=4)
- N-Gram 생성 방식:
1
2
(1) 텍스트를 N개의 단어 묶음으로 나눕니다.
(2) 각 N-Gram 묶음을 벡터화합니다.
- 특징: 단어의 순서를 반영하여 문맥을 고려합니다.
- 예시:
1
2
3
4
5
6
문장: "I love machine learning"
Unigram: ["I", "love", "machine", "learning"]
Bigram: ["I love", "love machine", "machine learning"]
Trigram: ["I love machine", "love machine learning"]
4-gram: ["I love machine learning"]
- 예시 코드:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
from sklearn.feature_extraction.text import CountVectorizer
bigram_vectorizer = CountVectorizer(ngram_range=(2, 2))
trigram_vectorizer = CountVectorizer(ngram_range=(3, 3))
documents = ["I love machine learning."]
bigram_matrix = bigram_vectorizer.fit_transform(documents)
trigram_matrix = trigram_vectorizer.fit_transform(documents)
print("Bigram:\\n", bigram_matrix.toarray())
print("Bigram Features:\\n", bigram_vectorizer.get_feature_names_out())
print("Trigram:\\n", trigram_matrix.toarray())
print("Trigram Features:\\n", trigram_vectorizer.get_feature_names_out())
-
분산 표현 (Distributed Representation)
분산 표현이란, 단어를 분산 벡터로 표현하여 단어 간의 유사성을 보존하는 방법입니다. 이는 단어의 의미를 벡터 공간 상에서 유사하게 배치하여 단어 간의 관계를 학습할 수 있게 합니다.
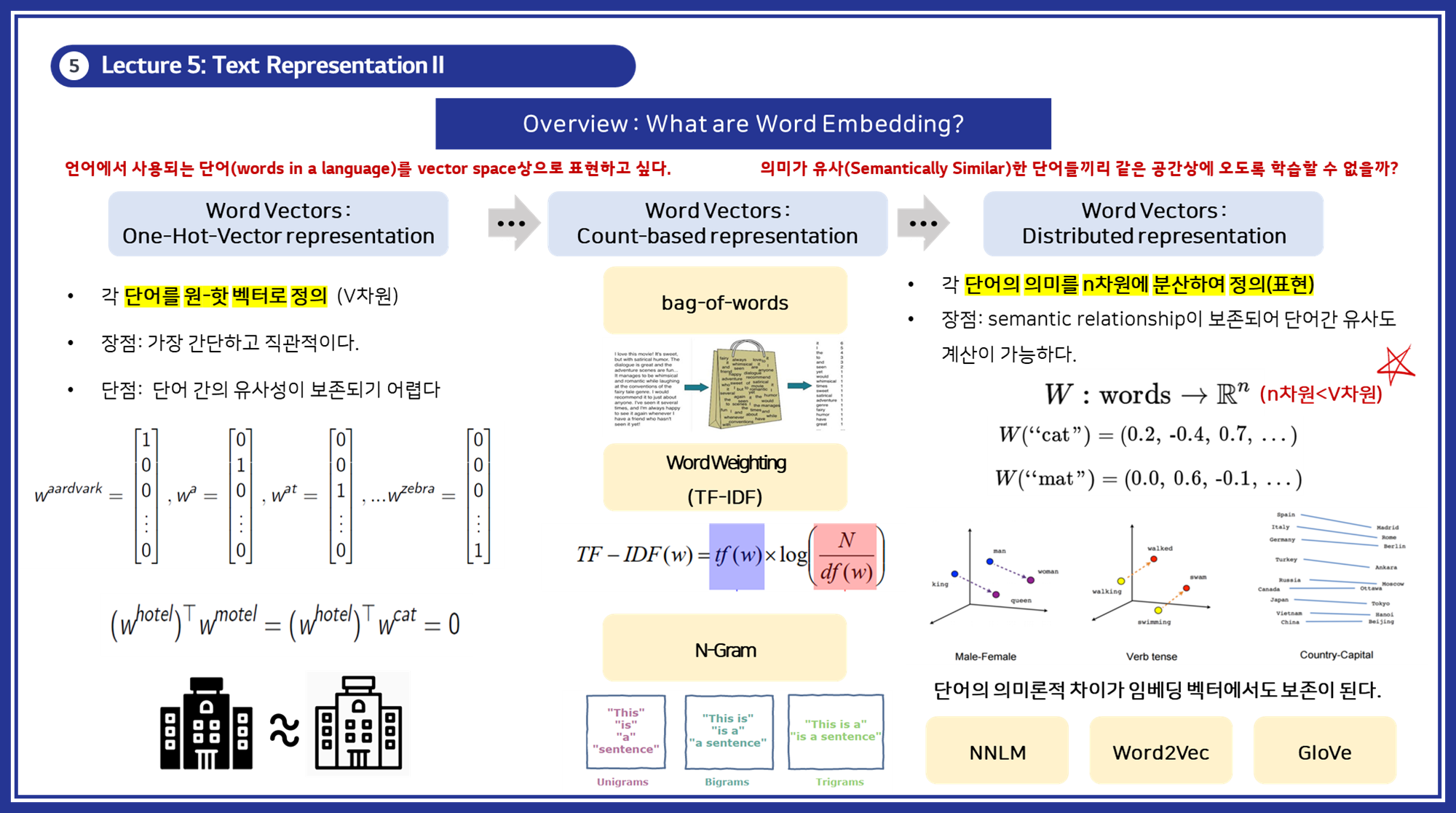
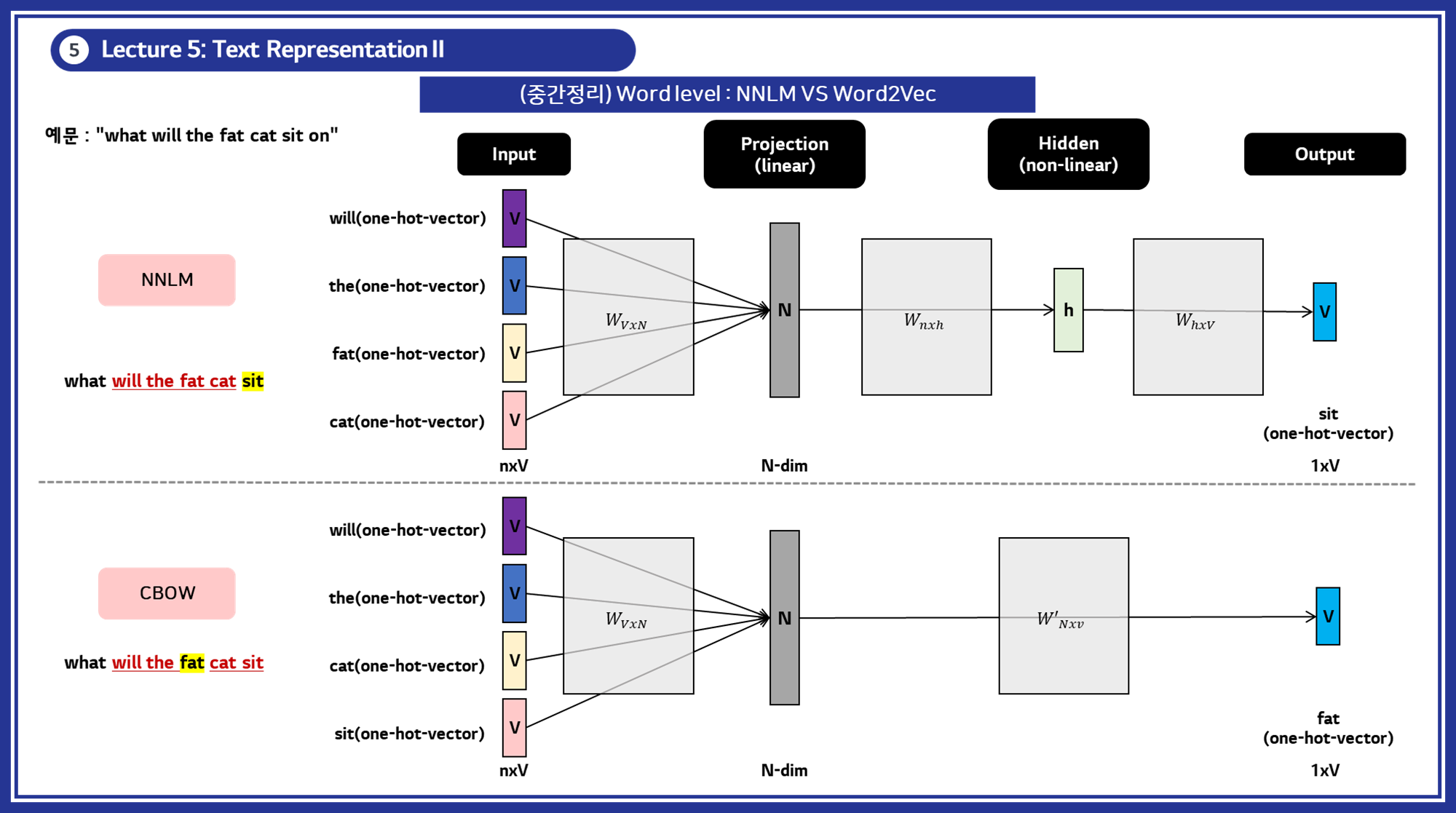
3.1 NNLM (NeuralNet Language Model)
- 개념: NNLM은 단어의 시퀀스를 입력받아 다음에 올 단어를 예측하는 방식으로 단어 벡터를 학습합니다. 입력된 단어 시퀀스를 고정 길이의 벡터로 변환하고, 이를 바탕으로 다음 단어의 확률 분포를 출력합니다. (RNN/LSTM 계열 모델)
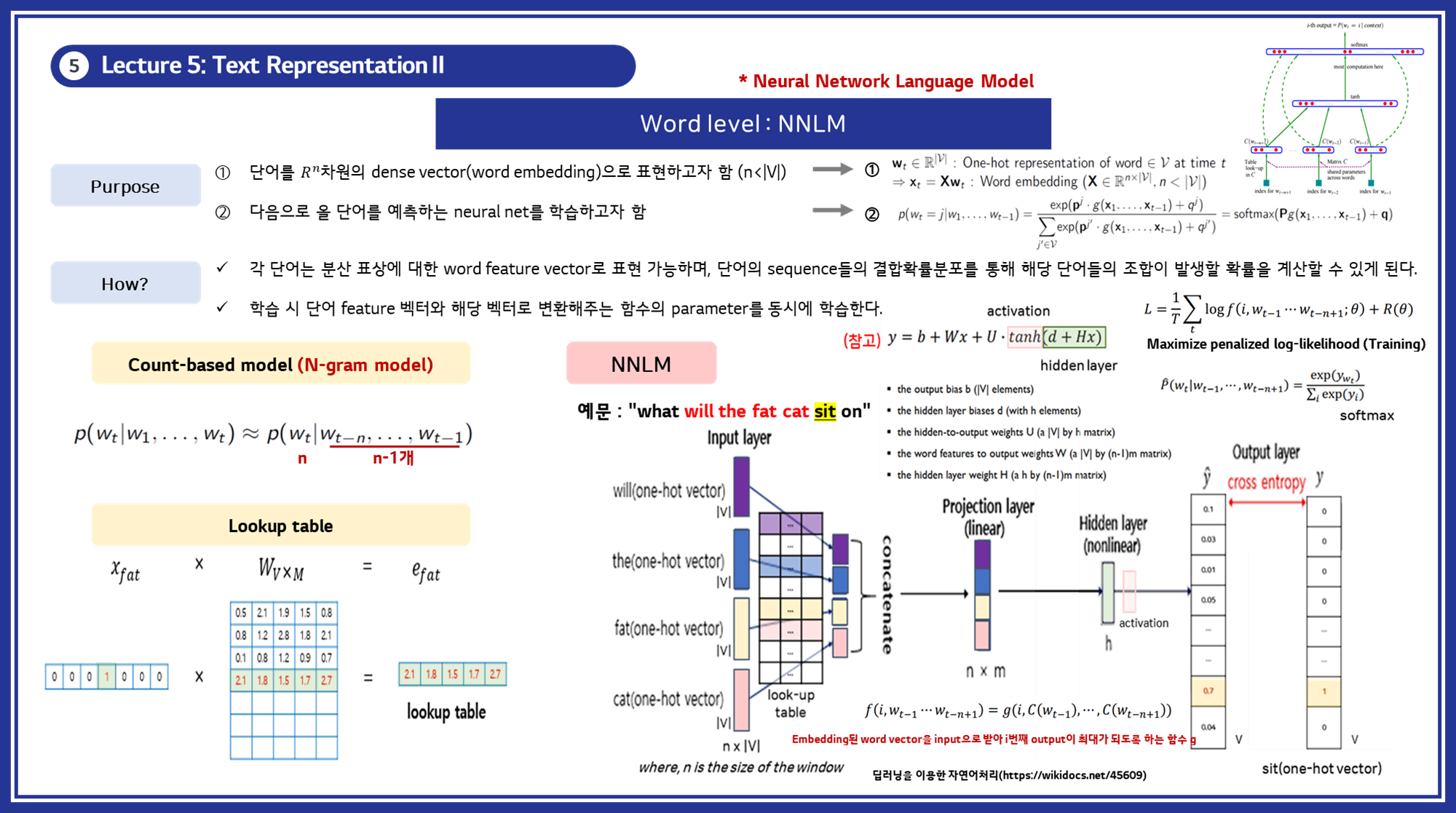
- NNLM 생성 방식:
1
2
3
(1) 단어 시퀀스를 입력받아 단어 임베딩 레이어를 통해 고정 길이의 벡터로 변환합니다.
(2) 은닉층을 거쳐 다음 단어의 확률 분포를 출력합니다.
(3) 모델을 학습하여 단어 임베딩 벡터를 최적화합니다.
- 특징: NNLM은 단어의 순서를 고려하여 문맥을 반영하며, 다음 단어를 예측하는 방식으로 단어 간의 관계를 학습합니다.
- 예시:
1
2
3
문장: "I love machine learning"
>>> 입력: ["I", "love", "machine"]
>>> 출력: "learning"
- 예시 코드:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, LSTM, Dense
# 샘플 데이터
sentences = ["I love machine learning", "Machine learning is fun", "I love deep learning"]
# 토크나이저 생성
tokenizer = Tokenizer()
tokenizer.fit_on_texts(sentences)
total_words = len(tokenizer.word_index) + 1
# 시퀀스 생성
input_sequences = []
for line in sentences:
token_list = tokenizer.texts_to_sequences([line])[0]
for i in range(1, len(token_list)):
n_gram_sequence = token_list[:i+1]
input_sequences.append(n_gram_sequence)
# 패딩
max_sequence_len = max([len(x) for x in input_sequences])
input_sequences = pad_sequences(input_sequences, maxlen=max_sequence_len, padding='pre')
# 특징과 레이블 분리
X, y = input_sequences[:,:-1], input_sequences[:,-1]
# 레이블 원-핫 인코딩
y = tf.keras.utils.to_categorical(y, num_classes=total_words)
# 모델 생성
model = Sequential()
model.add(Embedding(total_words, 10, input_length=max_sequence_len-1))
model.add(LSTM(100))
model.add(Dense(total_words, activation='softmax'))
# 모델 컴파일
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# 모델 학습
model.fit(X, y, epochs=100, verbose=1)
# 예측
seed_text = "I love"
next_words = 3
for _ in range(next_words):
token_list = tokenizer.texts_to_sequences([seed_text])[0]
token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding='pre')
predicted = model.predict(token_list, verbose=0)
output_word = tokenizer.index_word[np.argmax(predicted)]
seed_text += " " + output_word
print(seed_text)
3.2 Word2Vec
- 개념: 단어를 벡터 공간에 매핑하여 단어 간의 유사성을 보존하는 임베딩 기법입니다.
-
주요 모델로는
CBOW(Continuous Bag of Words)와Skip-gram이 있습니다. -
Word2Vec을 학습할 때는 CBOW와 Skip-gram 중 하나를 선택적으로 사용합니다. 두 방법은 서로 다른 접근 방식을 가지고 있으며, 각각의 장단점이 있습니다.
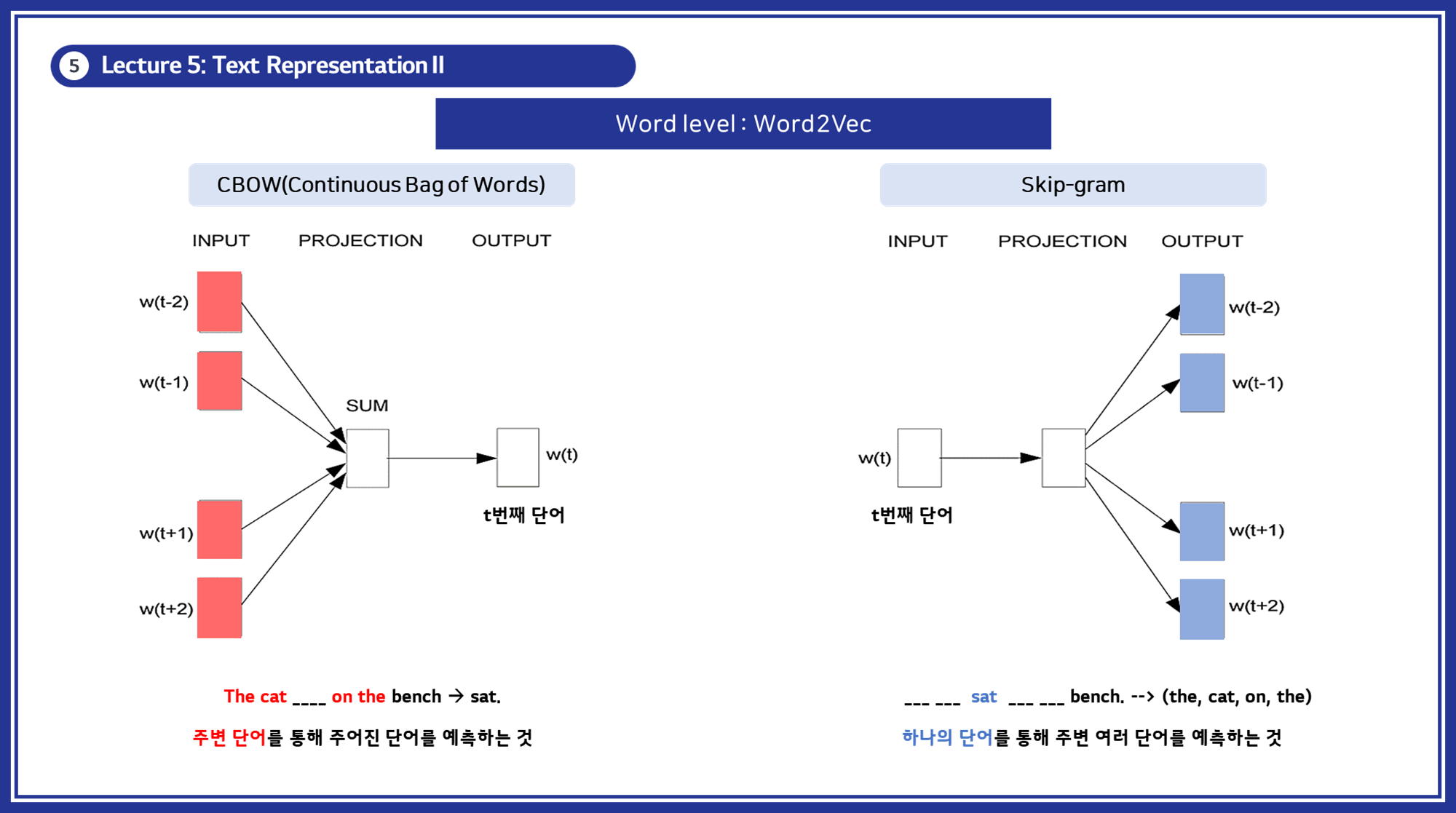
-
CBOW (Continuous Bag of Words):
- 주변 단어들로 중심 단어를 예측합니다.
- 일반적으로 작은 데이터셋에서 더 잘 작동합니다.
- 빈번한 단어에 대해 더 나은 성능을 보입니다.
-
Skip-gram:
- 중심 단어로 주변 단어들을 예측합니다.
- 대규모 데이터셋에서 더 좋은 성능을 보입니다.
- 드문 단어에 대해 더 나은 표현을 학습합니다.
-
- (Method 1) CBOW: 주변 단어들로 중심 단어를 예측.
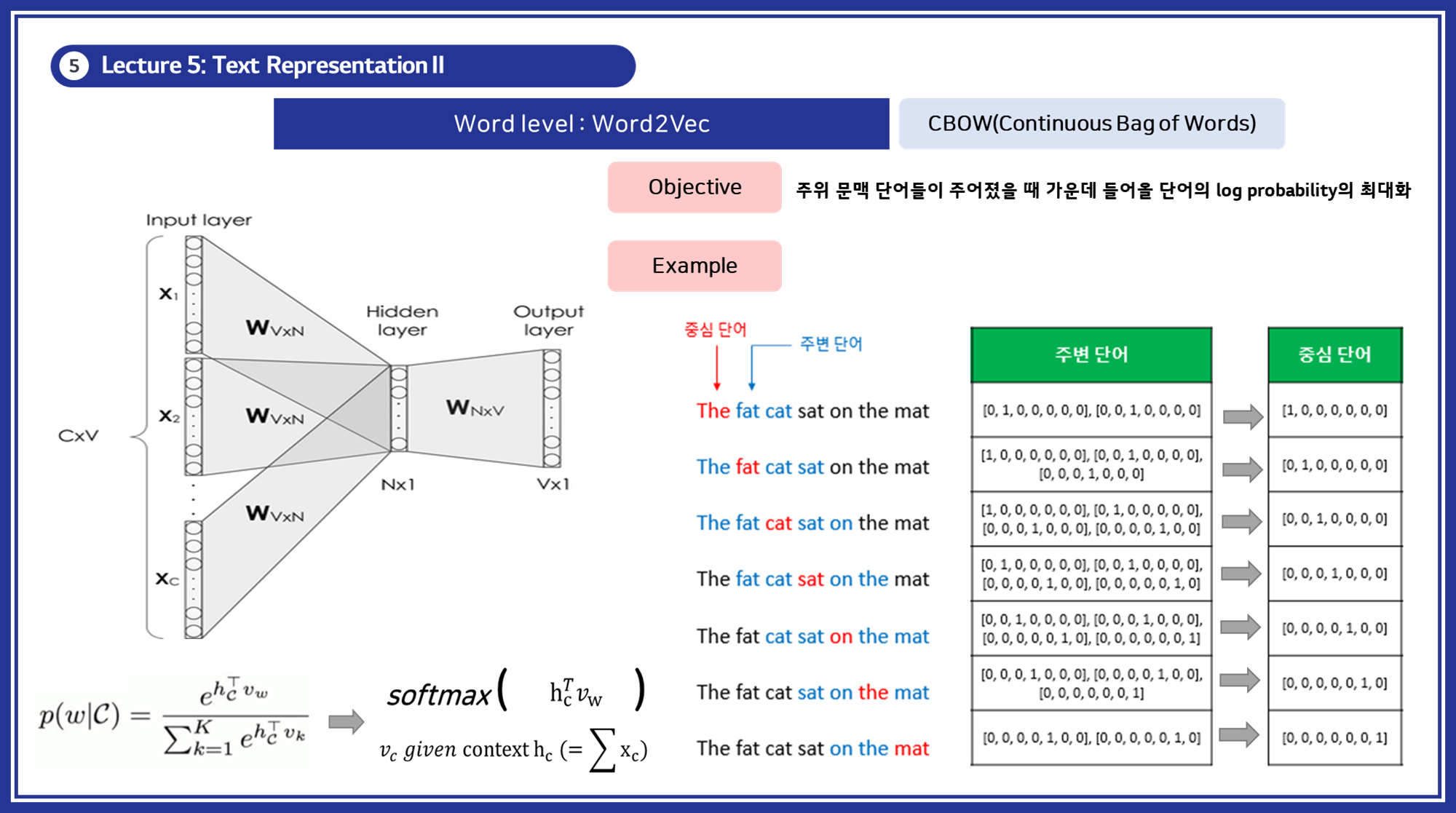
-
(Method 2) Skip-gram: 중심 단어로 주변 단어들을 예측.
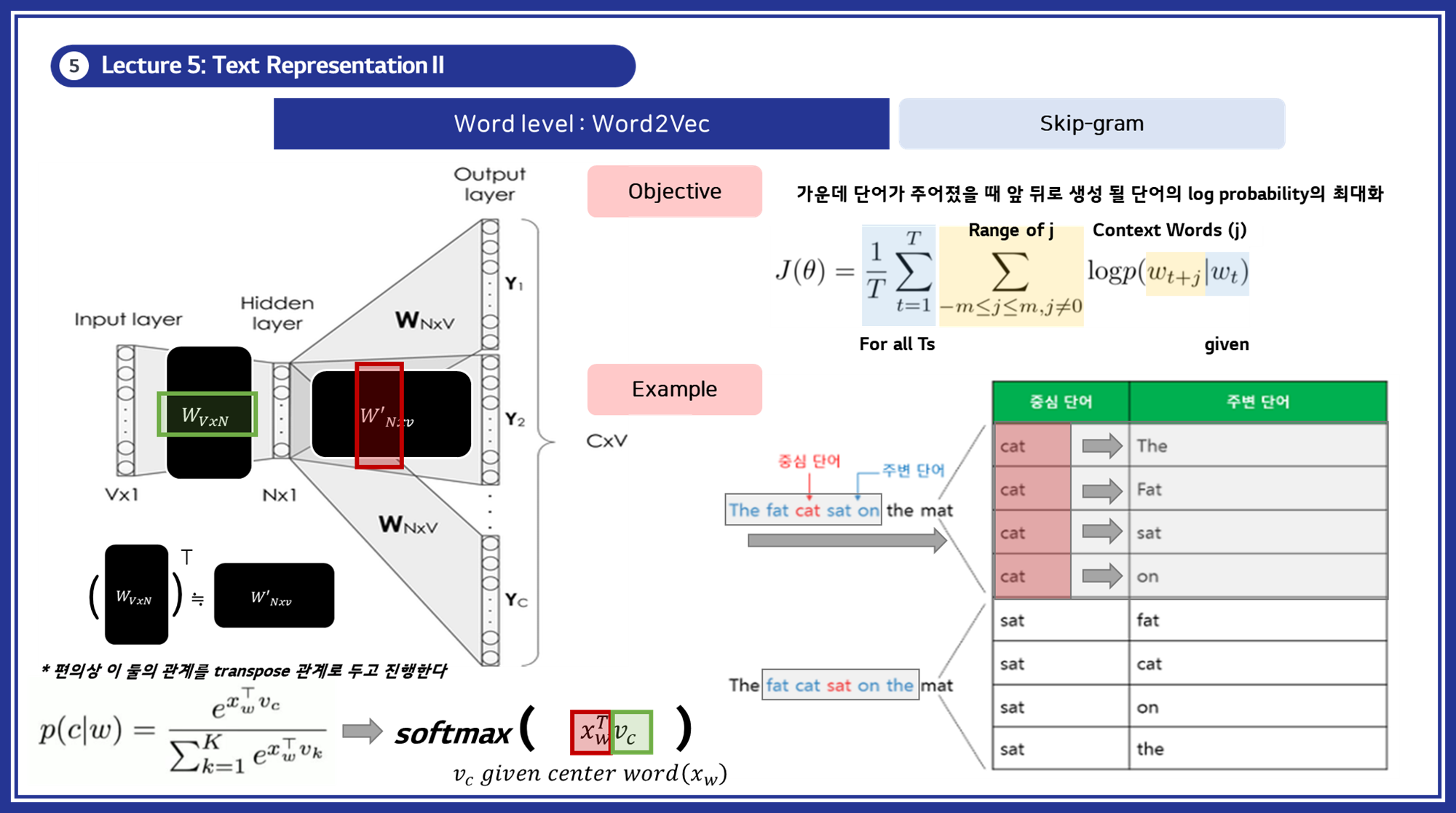
- 특징: 유사한 의미의 단어들이 가까운 벡터로 표현됩니다. 신경망을 통해 단어 벡터를 학습합니다.
- 예시:
1
2
3
4
5
6
7
8
9
10
11
문장: "The cat sat on the mat"
중심 단어: "sat"
주변 단어: ["The", "cat", ___, "on", "the", "mat"]
## CBOW: 주변 단어들 → 중심 단어 예측
>> 인풋: ["The", "cat", "on", "the", "mat"]
>> 아웃풋: "sat"
## Skip-gram: 중심 단어 → 주변 단어들 예측
>> 인풋: "sat"
>> 아웃풋: ["The", "cat", "on", "the", "mat"]
- 예시 코드:
1
2
3
4
5
6
7
8
9
from gensim.models import Word2Vec
sentences = [["the", "cat", "sat", "on", "the", "mat"],
["the", "dog", "sat", "on", "the", "couch"]]
model = Word2Vec(sentences, vector_size=100, window=5, min_count=1, sg=0) # CBOW
vector = model.wv['cat']
print(vector)
3.3 GloVe (Global Vectors for Word Representation)
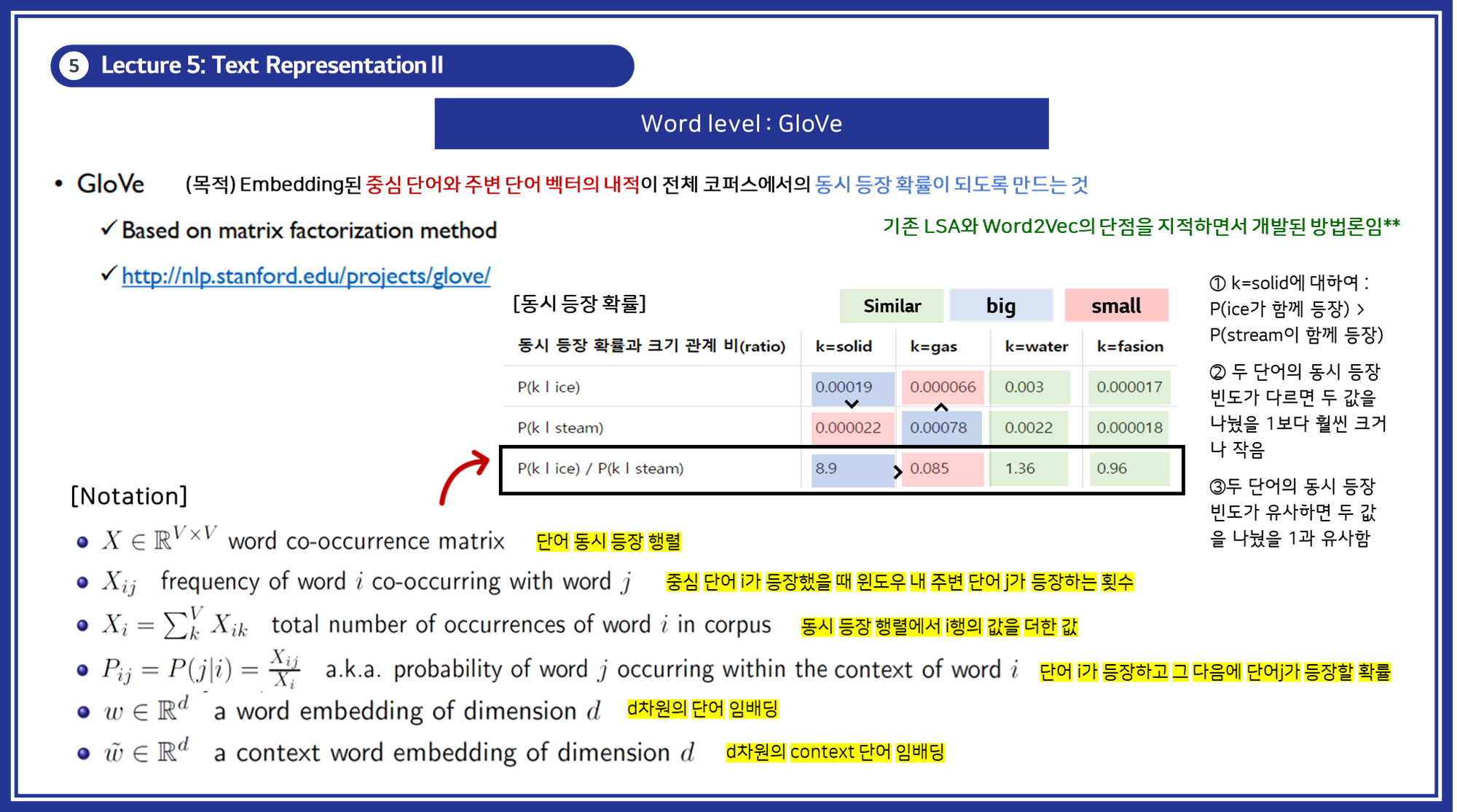
- 개념: 글로브(Global Vectors for Word Representation, GloVe)는 카운트 기반과 예측 기반을 모두 사용하는 방법론으로 2014년에 미국 스탠포드대학에서 개발한 단어 임베딩 방법론으로, 단어의 동시 등장 행렬을 활용하여 단어 벡터를 학습하는 방법입니다.
LSA 기법은 DTM(TDM)이나 TF-IDF 행렬과 같이 각 문서에서의 각 단어의 빈도수를 카운트 한 행렬이라는 전체적인 통계 정보를 입력으로 받아 차원을 축소(Truncated SVD)하여 잠재된 의미를 끌어내고자 합니다.- (단점) LSA는 카운트 기반으로 코퍼스의 전체적인 통계 정보를 고려하기는 하지만, King : Man = Queen : ? (Woman) 또는 Korea : Seoul = Japan : ? (Tokyo)와 같은 단어 의미의 유추 작업(Analogy task)에는 성능이 떨어집니다.
Word2Vec 기법은 CBOW와 Skip-gram이라는 딥러닝 학습방법을 활용하여 실제값과 예측값에 대한 오차를 손실 함수를 통해 줄여나가며 학습하며 잠재된 의미를 끌어내고자 합니다.- (단점) Word2Vec는 임베딩 벡터가 단어 간의 상관성을 고려하여 학습하기 때문에 유추 작업은 LSA보다 뛰어나지만, 윈도우 크기 내에서만 주변 단어를 고려하기 때문에 코퍼스의 전체적인 통계 정보를 반영하지 못합니다.
- Glove는 이러한 각각의 모델의 장점을 합쳐서 각각의 단점을 해결하고자 했습니다.
- GloVe 생성 방식:
동시 등장 행렬 (Co-occurrence Matrix)을 생성합니다.- 정의: 전체 코퍼스에서 각 단어 쌍이 특정 문맥 윈도우 내에서 함께 등장하는 빈도를 나타내는 행렬입니다.
- 구조: 행과 열이 모두 어휘의 단어들로 이루어진 정사각 행렬입니다.
- 값: 행렬의 각 셀 XijX_{ij}Xij는 단어 i의 문맥에서 단어 j가 등장한 횟수를 나타냅니다.
동시 등장 빈도 (Co-occurrence Frequency)를 기반으로 단어 벡터를 학습합니다.- 정의: 특정 단어 쌍이 정의된 문맥 윈도우 내에서 함께 등장하는 횟수입니다.
- 구조: 보통 중심 단어로부터 일정 거리(윈도우 크기) 내의 단어들을 문맥으로 간주하여 계산합니다.
- 값: 이 빈도는 단어 간의 관계를 나타내는 중요한 통계적 정보를 제공합니다.
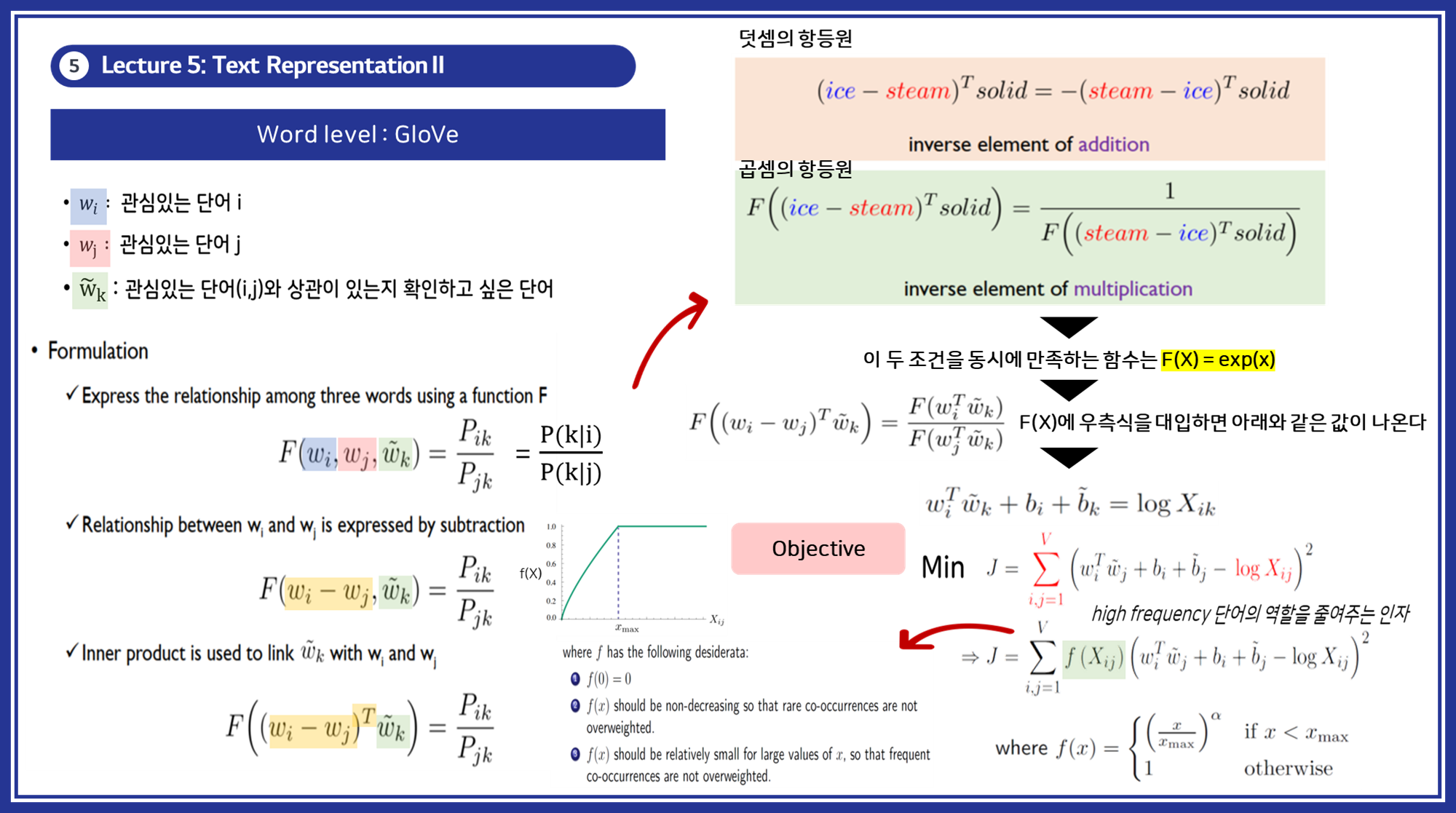
- 특징: 전체 코퍼스에서 단어가 함께 등장하는 빈도를 활용하여 전역적인 통계 정보를 반영합니다.
- 예시:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
문장들:
1. "The cat sits on the mat"
2. "The dog chases the cat"
3. "A cat and a dog play"
>> 문맥 윈도우 크기: 2 (중심 단어의 양쪽으로 2개의 단어까지 고려)
>> 동시 등장 행렬:
the cat sits on mat dog chases a and play
the 0 3 1 1 1 1 1 0 0 0
cat 3 0 1 1 1 2 1 2 1 1
sits 1 1 0 1 1 0 0 0 0 0
on 1 1 1 0 1 0 0 0 0 0
mat 1 1 1 1 0 0 0 0 0 0
dog 1 2 0 0 0 0 1 2 1 1
chases 1 1 0 0 0 1 0 0 0 0
a 0 2 0 0 0 2 0 0 1 1
and 0 1 0 0 0 1 0 1 0 1
play 0 1 0 0 0 1 0 1 1 0
- 예시 코드:
- GloVe 사용시, Stanford의 pre-trained 벡터를 다운로드 후 사용하실 수 있습니다.
- 이는 다음 링크에서 직접 받으실 수도 있습니다: https://nlp.stanford.edu/projects/glove/
- 아래는 사전 학습된 Glove 임배딩을 호출하고,
'cat'이라는 단어의 임배딩 값을 확인해보는 예제 코드입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
from urllib.request import urlretrieve
import zipfile
# glove 사전학습 파일 다운로드
urlretrieve("http://nlp.stanford.edu/data/glove.6B.zip", filename="glove.6B.zip")
# glove 사전학습 파일 압축 해제
with zipfile.ZipFile('glove.6B.zip', 'r') as zip_ref:
zip_ref.extractall()
from gensim.scripts.glove2word2vec import glove2word2vec
from gensim.models import KeyedVectors
# GloVe 파일 경로
glove_input_file = './glove.6B.100d.txt'
# 변환된 Word2Vec 파일 경로
word2vec_output_file = 'glove.6B.100d.word2vec.txt'
# GloVe 형식을 Word2Vec 형식으로 변환
glove2word2vec(glove_input_file, word2vec_output_file)
# 변환된 Word2Vec 형식의 파일을 로드
model = KeyedVectors.load_word2vec_format(word2vec_output_file, binary=False)
# 특정 단어의 벡터를 출력
vector = model['cat']
print(vector)
3.3 FastText
- 개념: FastText는 Facebook(현 Meta)에서 개발한 임배딩 기법으로, 단어 내부의 문자 n-gram을 활용하여 단어 벡터를 학습하는 방법입니다.
- Word2Vec와 FastText와의 가장 큰 차이점이라면 Word2Vec는 단어를 기본 단위로 생각한다면, FastText는 하나의 단어 안에도 단위들이 있다고 간주합니다. 즉, 단어의 형태소 정보를 반영합니다.

- FastText 생성 방식:
1
2
3
## Subword Model
(1) 단어를 문자 n-gram으로 분해합니다.
(2) 각 n-gram 벡터를 합산하여 단어 벡터를 생성합니다.
- 특징: 문자 n-gram을 사용하여 단어의 내부 구조를 반영하며, 모르는 단어(Out Of Vocabulary, OOV)도 효과적으로 학습합니다.
- 예시:
1
2
3
단어: "apple"
문자 n-gram: ["a", "ap", "app", "p", "pp", "ple", "e"]
벡터 학습: 각 문자 n-gram의 벡터를 합산하여 단어 벡터를 생성합니다.
- 예시 코드:
1
2
3
4
5
6
7
8
from gensim.models import FastText
sentences = [["the", "cat", "sat", "on", "the", "mat"],
["machine", "learning", "is", "fun"]]
model = FastText(sentences, vector_size=100, window=5, min_count=1)
vector = model.wv['cat']
print(vector)
-
문서 임베딩 (Document Embedding)
문서 전체를 하나의 벡터로 표현하는 기법입니다. 이는 문서의 내용을 종합적으로 고려하여 벡터화합니다.
4.1 단어 임베딩의 평균 (Averaging Word Embeddings)
- 개념: 가장 원초적인 방법으로, 문서 내의 모든 단어 임베딩 벡터의 평균을 구하여 문서 벡터를 생성하는 방법입니다.
- 생성 방식:
1
2
(1) 문서 내의 모든 단어를 임베딩 벡터로 변환합니다.
(2) 변환된 모든 단어 임베딩 벡터의 평균을 구합니다.
- 특징: 간단하고 계산이 빠르지만, 평균을 연산을 수행하기 때문에 문서 내 단어 순서나 문맥 정보를 반영하지 못합니다.
- 예시 코드:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
import numpy as np
from gensim.models import Word2Vec
sentences = [["I", "love", "machine", "learning"], ["Machine", "learning", "is", "fun"]]
word2vec_model = Word2Vec(sentences, vector_size=100, window=5, min_count=1, workers=4)
def average_word_embeddings(document):
vectors = [word2vec_model.wv[word] for word in document if word in word2vec_model.wv]
return np.mean(vectors, axis=0)
document = ["I", "love", "machine", "learning"]
document_vector = average_word_embeddings(document)
print(document_vector)
4.2 PV-DM (Distributed Memory Model of Paragraph Vectors)
- 개념: 문서와 단어를 동시에 임베딩하여 문서 벡터를 학습하는 방법입니다. 문맥 단어와 문서 벡터를 조합하여 중심 단어를 예측합니다.

- 생성 방식:
1
2
(1) 각 문서에 고유한 ID를 부여합니다.
(2) 문맥 단어와 문서 ID를 입력으로 받아 중심 단어를 예측합니다.
- 특징: 문서의 문맥 정보를 반영하여 문서 벡터를 학습합니다.
- 예시 코드:
1
2
3
4
5
6
7
8
9
from gensim.models.doc2vec import Doc2Vec, TaggedDocument
documents = [TaggedDocument(words=["I", "love", "machine", "learning"], tags=['doc1']),
TaggedDocument(words=["Machine", "learning", "is", "fun"], tags=['doc2'])]
model = Doc2Vec(documents, vector_size=100, window=2, min_count=1, workers=4, dm=1) # PV-DM
vector = model.dv['doc1']
print(vector)
4.3 PV-DBOW (Distributed Bag of Words Model of Paragraph Vectors)
- 개념: 단어 순서를 고려하지 않고 문서 벡터만으로 중심 단어를 예측하는 방법입니다. 단어의 순서나 문맥 정보를 반영하지 않으며, Skip-gram 모델과 유사합니다.

- 생성 방식:
1
2
(1) 각 문서에 고유한 ID를 부여합니다.
(2) 문서 ID를 입력으로 받아 중심 단어를 예측합니다.
- 특징: 단어의 순서를 고려하지 않으며, 문서 벡터만으로 단어를 예측합니다. 계산이 간단하고 빠릅니다.
- 예시 코드:
1
2
3
4
5
6
7
8
9
from gensim.models.doc2vec import Doc2Vec, TaggedDocument
documents = [TaggedDocument(words=["I", "love", "machine", "learning"], tags=['doc1']),
TaggedDocument(words=["Machine", "learning", "is", "fun"], tags=['doc2'])]
model = Doc2Vec(documents, vector_size=100, window=2, min_count=1, workers=4, dm=0) # PV-DBOW
vector = model.dv['doc1']
print(vector)
이번 포스트에서는 자연어 임베딩 학습을 위한 다양한 기법과 알고리즘에 대해 설명했습니다.
- 비정형 데이터를 정형 데이터로 변환하는 과정에서 Bag-of-Words(BoW), TF-IDF, N-Grams 모델을 통해 단어의 빈도와 순서를 반영한 벡터화를 살펴보았습니다.
- Word2Vec, GloVe, FastText를 통해 단어의 의미와 유사성을 반영한 분산 표현 기법을 살펴보았습니다.
- 또한, 문서 임베딩 기법을 통해 문서 전체를 벡터로 표현하는 방법도 설명하였습니다.
긴 글 읽어주셔서 감사합니다 💌