[트리] 트리 기반 ML 알고리즘
트리 기반 ML 알고리즘
트리 기반 머신러닝(ML) 알고리즘은 데이터의 특징을 기반으로 트리를 생성하여 예측(Regression) 또는 분류(Classification)를 수행하는 방법입니다. 이 알고리즘은 루트 노드에서 시작하여 내부 노드에서 데이터를 분할하고, 리프 노드에서 최종 예측값을 산출합니다. 트리 기반 알고리즘은 데이터의 구조를 시각적으로 표현할 수 있어 해석이 용이하며, 다양한 데이터셋에 대해 높은 성능을 보입니다.
알고리즘의 장단점
장점
- 해석 용이성 (Interpretability): 트리 구조는 시각적으로 이해하기 쉽고, 모델의 결정 과정을 명확하게 보여줍니다. 이는 모델이 어떻게 예측을 수행하는지 쉽게 설명할 수 있게 해주며, 특히 의사 결정이 중요한 분야에서 유용합니다.
- 비선형 관계 모델링 (Non-linear Relationships): 트리 기반 알고리즘은 비선형적인 데이터 관계를 잘 포착할 수 있어 복잡한 데이터 구조를 효과적으로 처리할 수 있습니다.
- 특징 선택 (Feature Selection): 알고리즘이 중요한 특징을 자동으로 선택하고 불필요한 특징을 무시하여 모델의 성능을 향상시킵니다.
- 다양한 데이터 타입 처리 (Handling Various Data Types): 연속형 및 범주형 데이터를 모두 처리할 수 있어 다양한 유형의 데이터셋에 유연하게 적용할 수 있습니다.
- 로버스트함 (Robustness): 트리 기반 모델은 이상치(outliers)나 잡음(noise)에 강한 특성을 보입니다. 이는 모델이 다양한 데이터 조건에서도 안정적으로 작동하게 합니다.
단점
- 과적합 위험 (Risk of Overfitting): 단일 의사결정나무는 과적합에 민감하여 학습 데이터에 너무 맞춰질 수 있습니다. 이를 방지하기 위해 가지치기(pruning) 등의 기법이 필요합니다.
- 높은 계산 비용 (High Computational Cost): 대규모 데이터셋에서 트리를 학습하고 예측하는 데 시간이 많이 소요될 수 있습니다. 특히 부스팅 계열 모델(예: GBM, AdaBoost 등)은 많은 트리를 학습해야 하므로 계산 비용이 더 높습니다.
- 데이터 민감성 (Data Sensitivity): 트리 기반 모델은 데이터의 작은 변화에도 민감하게 반응할 수 있습니다. 이는 모델의 안정성을 저하시킬 수 있습니다.
- 변수 간 상호작용 복잡성 (Complexity of Interactions): 트리 구조가 깊어질수록 변수 간 상호작용이 복잡해질 수 있으며, 이는 모델의 해석을 어렵게 만들 수 있습니다.
- 결정 경계 불연속성 (Discontinuity of Decision Boundaries): 트리 기반 모델은 결정 경계가 불연속적이어서, 실제 데이터의 연속성을 잘 반영하지 못할 수 있습니다. 이는 특히 경계가 중요한 연속형 변수에 대해 성능 저하를 초래할 수 있습니다.
트리 기반 ML 알고리즘의 발전
트리 기반 회귀/분류 알고리즘의 역사는 머신러닝 알고리즘의 발전 과정에서 중요한 위치를 차지합니다. 각 알고리즘은 그 이전의 알고리즘의 한계를 보완하고 성능을 향상시키기 위해 개발되었습니다.
아래에 주요 트리 기반 알고리즘의 발전 순서와 특징을 설명하겠습니다. 아래 기입한 역사는 찾은 논문 날짜를 토대로 작성하였습니다. (실제 알고리즘 개발 날짜와 상이할 수 있습니다!!)
1. Decision Tree (의사결정나무)
- 역사: 1960년대 (논문 링크)
- 특징: 데이터의 특징에 따라 분할을 반복하여 예측을 수행합니다. ID3, C4.5, CART 등의 알고리즘이 포함됩니다.
- 예시: 엔트로피, 지니 불순도를 사용하여 분할 기준을 정함.
2. Random Forest (랜덤 포레스트)
- 역사: 2001년 (Leo Breiman) (논문 링크)
- 특징: 여러 개의 결정 트리를 앙상블하여 예측 성능을 향상시킵니다. 각 트리는 부트스트랩 샘플링과 무작위 특징 선택을 통해 생성됩니다.
- 예시: 배깅(bagging) 기법을 사용하여 여러 트리의 예측을 평균 내거나 다수결로 결합.
3. Gradient Boosting (그래디언트 부스팅)
- 역사: 2001년 (Jerome Friedman) (논문 링크)
- 특징: 이전 트리의 오차를 줄이기 위해 순차적으로 트리를 추가합니다. 주로 회귀 분석에 사용되지만, 분류에도 사용 가능합니다.
- 예시: 손실 함수를 최소화하는 방향으로 트리를 학습시킴.
4. AdaBoost (Adaptive Boosting)
- 역사: 1996년 (Yoav Freund, Robert Schapire) (논문 링크)
- 특징: 잘못 분류된 샘플에 가중치를 더 부여하여 다음 트리를 학습시킵니다. 결과적으로 강력한 학습기를 만듭니다.
- 예시: 각 학습기의 가중치를 조정하여 최종 예측 모델을 구성.
5. Extra Trees (Extremely Randomized Trees)
- 역사: 2006년 (Pierre Geurts, Damien Ernst, Louis Wehenkel) (논문 링크)
- 특징: 랜덤 포레스트와 유사하지만, 트리의 분할 기준을 완전히 무작위로 선택합니다. 일반적으로 더 많은 트리를 필요로 하지만, 높은 성능을 보입니다.
- 예시: 분할 시 무작위로 특징과 분할점을 선택.
6. XGBoost (Extreme Gradient Boosting)
- 역사: 2016년 (Tianqi Chen) (논문 링크)
- 특징: 그래디언트 부스팅의 효율성과 성능을 개선한 라이브러리입니다. 정규화와 병렬 처리 등의 최적화 기법을 사용합니다.
- 예시: 정규화 항을 추가하여 과적합 방지.
7. LightGBM (Light Gradient Boosting Machine)
- 역사: 2017년 (Microsoft) (논문 링크)
- 특징: 대용량 데이터와 고차원 데이터를 효율적으로 처리할 수 있도록 설계되었습니다. 리프 중심 트리 분할 방식을 사용합니다.
- 예시: Gradient-based One-Side Sampling (GOSS)와 Exclusive Feature Bundling (EFB) 기법 사용.
8. CatBoost (Categorical Boosting)
- 역사: 2018년 (Yandex) (논문 링크)
- 특징: 범주형 변수를 효과적으로 처리할 수 있도록 설계되었습니다. 순차 부스팅과 그라디언트 계산에 최적화된 알고리즘을 사용합니다.
- 예시: 순차적인 순서에 따라 카테고리형 변수의 평균을 사용하여 변수를 처리.
9. Histogram-based Gradient Boosting (HGBT)
- 역사: 특정하기 어려움. (LightGBM 개발 당시, 히스토그램 기반 알고리즘의 효율성을 확인함 => 이를 발전시킨 형태가 바로 HGBT)
- 특징: 히스토그램을 사용하여 데이터의 연속 변수를 버킷으로 그룹화하여 처리 속도를 높입니다.
- 예시: 각 특징을 히스토그램으로 변환하여 빠르게 최적 분할을 찾음.
이 외에도 트리 기반 알고리즘의 변형과 개선이 계속해서 이루어지고 있으며, 최신 기술 동향에 따라 더 나은 성능을 목표로 하는 새로운 알고리즘이 개발되고 있습니다. 아래에 위에서 언급한 주요 트리 기반 알고리즘의 역사적 순서와 특징을 설명하고, 각 알고리즘의 개념 및 원리, 파이썬 코드 예제를 소개합니다.
1. Decision Tree (의사결정나무)
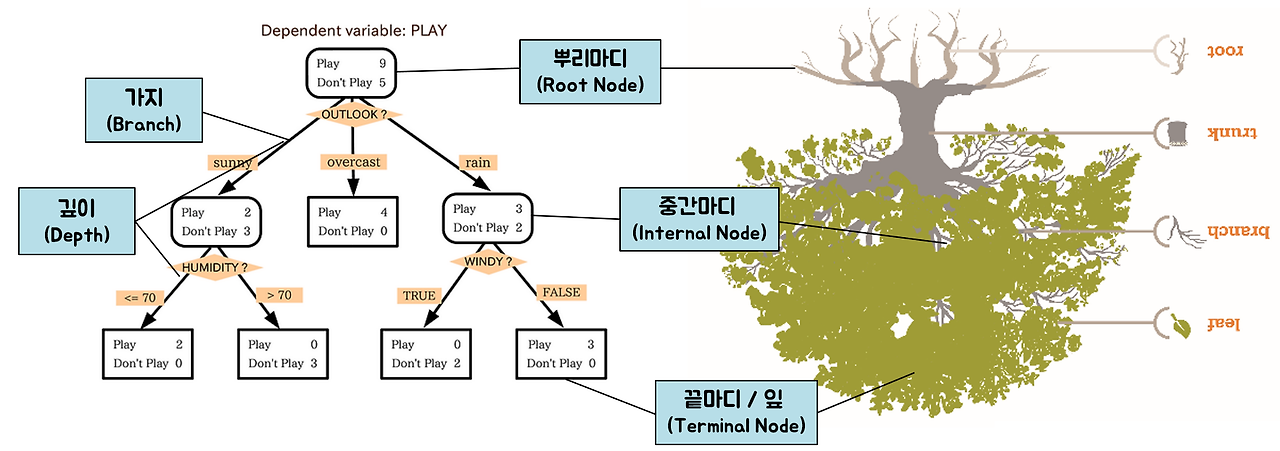
출처: 직장인 고니의 데이터 분석
개념 및 원리
의사결정나무는 데이터의 특징을 기반으로 분할하여 예측을 수행하는 모델입니다. 트리는 루트 노드에서 시작하여 내부 노드에서 데이터의 특징에 따라 분할되고, 리프 노드에서 최종 예측값을 산출합니다. 의사결정나무의 주요 개념은 다음과 같습니다:
- 분할 기준 (Split Criterion): 데이터 분할의 기준을 정하는 방법으로, 엔트로피(entropy)와 지니 불순도(gini impurity)가 대표적입니다.
- 정보 획득 (Information Gain): 특정 분할 기준에 의해 데이터가 얼마나 잘 분할되는지를 측정합니다. 정보 획득이 최대화되는 방향으로 트리를 분할합니다.
- 가지치기 (Pruning): 과적합을 방지하기 위해 트리의 성장을 제한하거나 불필요한 가지를 제거합니다.
파이썬 코드 예제
아래는 scikit-learn 라이브러리를 사용하여 의사결정나무를 구현하는 예제입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
# 데이터 로드
iris = load_iris()
X, y = iris.data, iris.target
# 학습 데이터와 테스트 데이터로 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 의사결정나무 모델 생성 및 학습
clf = DecisionTreeClassifier(criterion='gini', max_depth=3, random_state=42)
clf.fit(X_train, y_train)
# 예측 및 평가
y_pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
# 트리 시각화
plt.figure(figsize=(20, 10))
plot_tree(clf, feature_names=iris.feature_names, class_names=iris.target_names, filled=True)
plt.show()
코드 설명
- 데이터 로드 및 분할:
load_iris()함수를 사용하여 아이리스 데이터를 로드하고,train_test_split()을 통해 학습 데이터와 테스트 데이터로 분할합니다. - 모델 생성 및 학습:
DecisionTreeClassifier를 사용하여 의사결정나무 모델을 생성하고,fit()함수를 사용하여 학습시킵니다. 여기서는 지니 불순도를 분할 기준으로 사용하고, 최대 깊이를 3으로 설정했습니다. - 예측 및 평가: 학습된 모델로 테스트 데이터를 예측하고, 정확도를 계산합니다.
- 트리 시각화:
plot_tree()함수를 사용하여 학습된 트리를 시각화합니다. 트리의 각 노드는 특징과 클래스에 대한 정보를 포함하고 있습니다.
2. Random Forest (랜덤 포레스트)
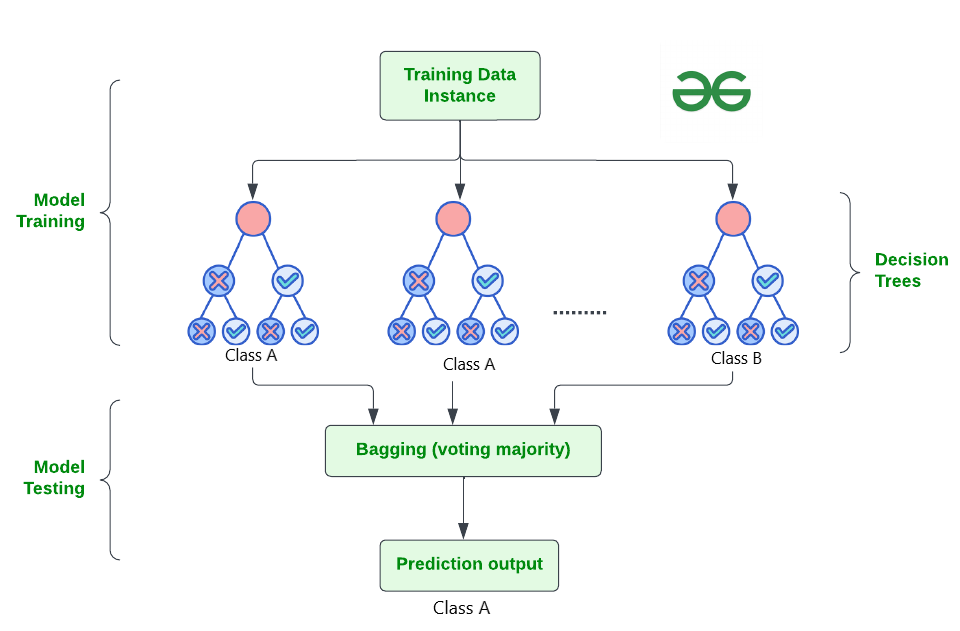
출처 : GeeksforGeeks
개념 및 원리
랜덤 포레스트는 여러 개의 의사결정나무를 앙상블하여 예측 성능을 향상시키는 방법입니다. 각 의사결정나무는 독립적으로 학습되며, 최종 예측은 각 나무의 예측을 결합하여 이루어집니다. 랜덤 포레스트의 주요 개념은 다음과 같습니다:
- 배깅 (Bagging): 부트스트랩 샘플링을 통해 여러 트레이닝 세트를 생성하고, 각 세트에 대해 독립적인 모델을 학습시킵니다.
- 랜덤 특징 선택: 각 노드에서 분할할 때 전체 특징 중 무작위로 선택된 일부 특징만을 사용하여 분할합니다.
- 앙상블: 각 나무의 예측을 평균 내거나 다수결 투표를 통해 최종 예측을 수행합니다.
파이썬 코드 예제
아래는 scikit-learn 라이브러리를 사용하여 랜덤 포레스트를 구현하는 예제입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
# 데이터 로드
iris = load_iris()
X, y = iris.data, iris.target
# 학습 데이터와 테스트 데이터로 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 랜덤 포레스트 모델 생성 및 학습
clf = RandomForestClassifier(n_estimators=100, max_depth=3, random_state=42)
clf.fit(X_train, y_train)
# 예측 및 평가
y_pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
# 중요 특징 시각화
feature_importances = clf.feature_importances_
features = iris.feature_names
importance_df = pd.DataFrame({'Feature': features, 'Importance': feature_importances})
plt.figure(figsize=(10, 6))
sns.barplot(x='Importance', y='Feature', data=importance_df)
plt.title('Feature Importance in Random Forest')
plt.show()
코드 설명
- 데이터 로드 및 분할:
load_iris()함수를 사용하여 아이리스 데이터를 로드하고,train_test_split()을 통해 학습 데이터와 테스트 데이터로 분할합니다. - 모델 생성 및 학습:
RandomForestClassifier를 사용하여 랜덤 포레스트 모델을 생성하고,fit()함수를 사용하여 학습시킵니다. 여기서는 100개의 트리를 사용하고, 각 트리의 최대 깊이를 3으로 설정했습니다. - 예측 및 평가: 학습된 모델로 테스트 데이터를 예측하고, 정확도를 계산합니다.
- 중요 특징 시각화:
feature_importances_속성을 사용하여 각 특징의 중요도를 계산하고,seaborn을 사용하여 바 그래프로 시각화합니다.
3. Gradient Boosting (그래디언트 부스팅)
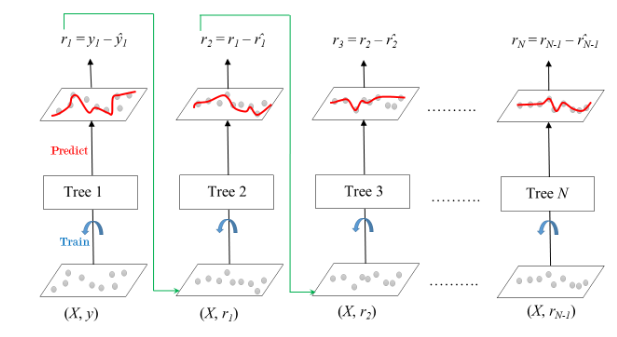
출처 : GeeksforGeeks
개념 및 원리
그래디언트 부스팅은 순차적으로 트리를 추가하여 예측 성능을 향상시키는 앙상블 학습 방법입니다. 각 트리는 이전 트리의 오차를 줄이기 위해 학습되며, 손실 함수를 최소화하는 방향으로 트리를 추가합니다. 그래디언트 부스팅의 주요 개념은 다음과 같습니다:
- 순차적 학습: 모델을 순차적으로 학습시키며, 각 단계에서 이전 모델의 잔여 오차를 줄이기 위해 새로운 모델을 추가합니다.
- 손실 함수 (Loss Function): 예측 오차를 평가하기 위한 함수로, 주로 회귀에서는 평균 제곱 오차(MSE), 분류에서는 로그 손실(Log Loss)을 사용합니다.
- 그라디언트 계산: 손실 함수를 최소화하기 위해 각 단계에서 잔여 오차의 그라디언트를 계산하여 모델을 업데이트합니다.
파이썬 코드 예제
아래는 scikit-learn 라이브러리를 사용하여 그래디언트 부스팅을 구현하는 예제입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
from sklearn.datasets import load_iris
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
# 데이터 로드
iris = load_iris()
X, y = iris.data, iris.target
# 학습 데이터와 테스트 데이터로 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 그래디언트 부스팅 모델 생성 및 학습
clf = GradientBoostingClassifier(n
_estimators=100, learning_rate=0.1, max_depth=3, random_state=42)
clf.fit(X_train, y_train)
# 예측 및 평가
y_pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
# 중요 특징 시각화
feature_importances = clf.feature_importances_
features = iris.feature_names
importance_df = pd.DataFrame({'Feature': features, 'Importance': feature_importances})
plt.figure(figsize=(10, 6))
sns.barplot(x='Importance', y='Feature', data=importance_df)
plt.title('Feature Importance in Gradient Boosting')
plt.show()
코드 설명
- 데이터 로드 및 분할:
load_iris()함수를 사용하여 아이리스 데이터를 로드하고,train_test_split()을 통해 학습 데이터와 테스트 데이터로 분할합니다. - 모델 생성 및 학습:
GradientBoostingClassifier를 사용하여 그래디언트 부스팅 모델을 생성하고,fit()함수를 사용하여 학습시킵니다. 여기서는 100개의 트리, 학습률 0.1, 최대 깊이 3으로 설정했습니다. - 예측 및 평가: 학습된 모델로 테스트 데이터를 예측하고, 정확도를 계산합니다.
- 중요 특징 시각화:
feature_importances_속성을 사용하여 각 특징의 중요도를 계산하고,seaborn을 사용하여 바 그래프로 시각화합니다.
4. AdaBoost (Adaptive Boosting)
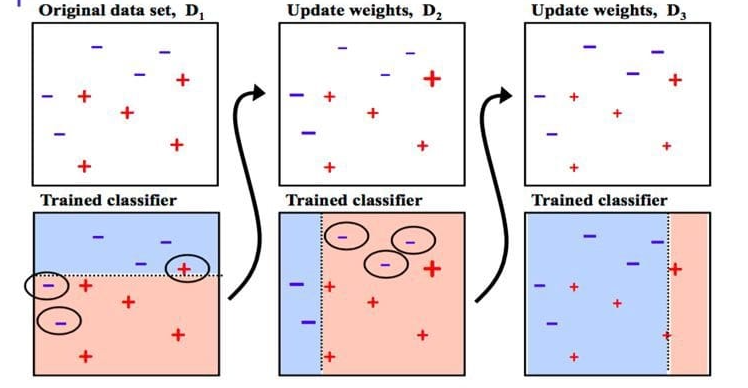
출처 : Towards AI
개념 및 원리
AdaBoost (Adaptive Boosting)는 약한 학습기(Weak Learner)를 결합하여 강한 학습기(Strong Learner)를 만드는 앙상블 학습 방법입니다. AdaBoost는 초기 학습기의 오류를 보완하기 위해 후속 학습기에 가중치를 부여하여 점차적으로 성능을 향상시킵니다. 주요 개념은 다음과 같습니다:
- 가중치 업데이트: 초기 학습기의 오류가 큰 데이터 포인트에 더 많은 가중치를 부여하여 다음 학습기가 이 오류를 줄이도록 합니다.
- 순차적 학습: 각 학습기는 이전 학습기의 오류를 줄이기 위해 순차적으로 학습됩니다.
- 앙상블: 최종 예측은 모든 학습기의 가중치가 부여된 투표를 통해 결정됩니다.
파이썬 코드 예제
아래는 scikit-learn 라이브러리를 사용하여 AdaBoost를 구현하는 예제입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
from sklearn.datasets import load_iris
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
# 데이터 로드
iris = load_iris()
X, y = iris.data, iris.target
# 학습 데이터와 테스트 데이터로 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# AdaBoost 모델 생성 및 학습
base_estimator = DecisionTreeClassifier(max_depth=1, random_state=42)
clf = AdaBoostClassifier(estimator=base_estimator, n_estimators=50, learning_rate=1.0, random_state=42)
clf.fit(X_train, y_train)
# 예측 및 평가
y_pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
# 중요 특징 시각화
feature_importances = clf.feature_importances_
features = iris.feature_names
importance_df = pd.DataFrame({'Feature': features, 'Importance': feature_importances})
plt.figure(figsize=(10, 6))
sns.barplot(x='Importance', y='Feature', data=importance_df)
plt.title('Feature Importance in AdaBoost')
plt.show()
코드 설명
- 데이터 로드 및 분할:
load_iris()함수를 사용하여 아이리스 데이터를 로드하고,train_test_split()을 통해 학습 데이터와 테스트 데이터로 분할합니다. - 모델 생성 및 학습:
DecisionTreeClassifier를 약한 학습기로 사용하여AdaBoostClassifier를 생성하고,fit()함수를 사용하여 학습시킵니다. 여기서는 최대 깊이 1의 의사결정나무를 약한 학습기로 사용하며, 50개의 학습기를 사용합니다. - 예측 및 평가: 학습된 모델로 테스트 데이터를 예측하고, 정확도를 계산합니다.
- 중요 특징 시각화:
feature_importances_속성을 사용하여 각 특징의 중요도를 계산하고,seaborn을 사용하여 바 그래프로 시각화합니다.
5. Extra Trees (Extremely Randomized Trees)
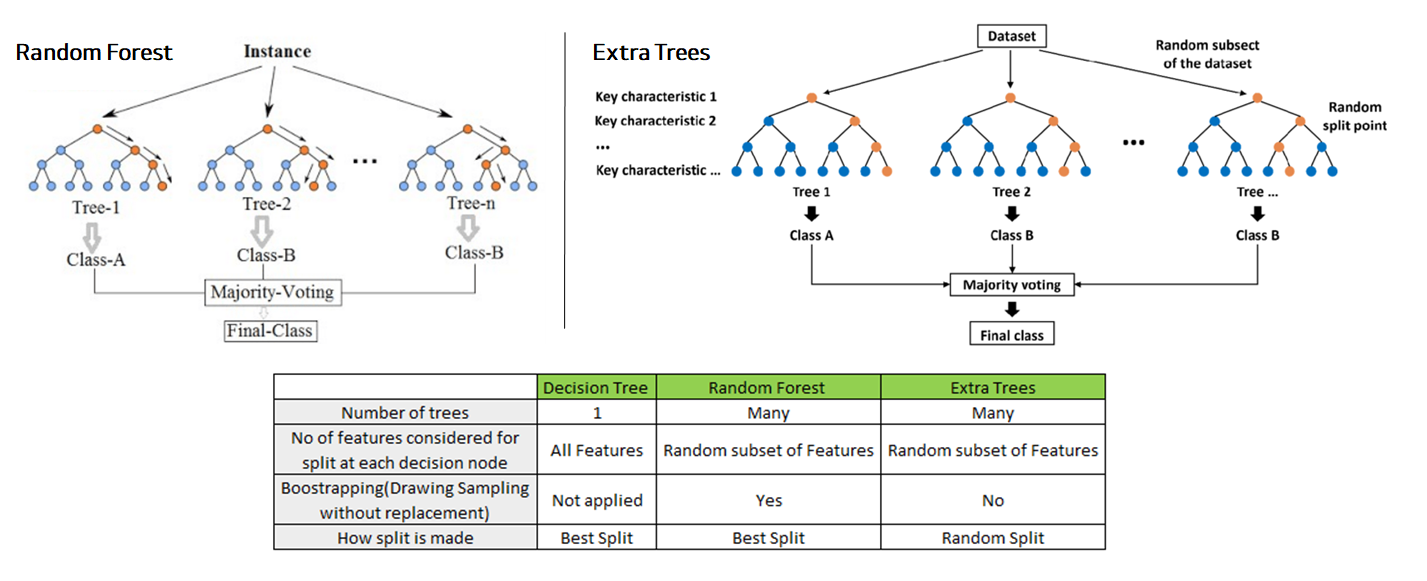
출처 : stackexchange, difference-between-random-forest-and-extremely-randomized-trees
개념 및 원리
Extra Trees (Extremely Randomized Trees)는 랜덤 포레스트와 유사하지만, 더 많은 무작위성을 도입하여 모델을 학습시키는 앙상블 방법입니다. 랜덤 포레스트가 각 노드에서 최적의 분할을 찾는 반면, Extra Trees는 무작위로 선택된 분할 기준을 사용하여 트리를 구성합니다. 이로 인해 모델의 편향은 약간 증가할 수 있지만, 분산은 감소하여 과적합을 방지하는 데 도움이 됩니다. 주요 개념은 다음과 같습니다:
- 완전 무작위 분할: 각 노드에서 무작위로 선택된 분할 기준을 사용하여 분할합니다.
- 배깅 (Bagging): 여러 개의 트리를 독립적으로 학습시키고, 예측 결과를 앙상블합니다.
- 특징의 무작위 선택: 각 노드에서 분할할 때 사용할 특징을 무작위로 선택합니다.
💡 랜덤 포레스트와 차이
저는 개인적으로 랜덤 포레스트와 엑스트라 트리의 개념이 많이 혼동스럽더라고요… 그래서 정리했습니다!
- 두 알고리즘은 기본적으로 앙상블(ensemble) 방식의 의사결정 나무(decision tree) 모델이라는 점에서 유사하지만, 몇 가지 중요한 차이점이 있습니다.
랜덤 포레스트(Random Forest)와엑스트라 트리(Extra Trees)의 차이점을 명확하게 이해하기 위해서는 두 알고리즘의 노드 분할 방식과 샘플링 방식의 차이를 주의 깊게 살펴봐야 합니다.
🌳🌳 1. 랜덤 포레스트 (Random Forest) 🌳🌳
- 부트스트랩 샘플링 (Bootstrap Sampling, 상이):
- 각 트리는 원본 데이터에서 무작위로 샘플을 선택하여 학습함.
- 샘플링은 복원 추출 방식으로 이루어져 일부 데이터 포인트가 여러 번 선택될 수 있음.
- 피처 무작위성 (Feature Sampling, 동일):
- 각 노드를 분할할 때, 전체 피처 중 무작위로 선택된 피처의 부분집합을 사용함.
- 노드 샘플 분할 (Node Sample Splits, 상이):
- 각 노드에서 최적의 분할을 찾기 위해 선택된 피처의 부분집합을 사용함.
- 선택된 피처들 중에서 분할 기준이 되는 임계값을 찾음.
🌲🌲 2. 엑스트라 트리 (Extra Trees) 🌲🌲
- 부트스트랩 샘플링 없음 (No Bootstrap Sampling, 상이):
- 부트스트랩 샘플링을 사용하지 않음.
- 전체 데이터셋을 사용하여 각 트리를 학습함.
- 피처 무작위성 (Feature Sampling, 동일):
- 각 노드를 분할할 때, 전체 피처 중 무작위로 선택된 피처의 부분집합을 사용함.
- 노드 랜덤 분할 (Node Random Splits, 상이):
- 선택된 피처에 대해 분할 임계값을 무작위로 선택함.
- 여러 무작위 분할 중 가장 좋은 분할을 선택함.
- 이 과정에서 무작위성이 더 많이 도입되어, 계산 속도가 빨라지고 트리들이 서로 더 독립적임.
파이썬 코드 예제
아래는 scikit-learn 라이브러리를 사용하여 Extra Trees를 구현하는 예제입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
from sklearn.datasets import load_iris
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
# 데이터 로드
iris = load_iris()
X, y = iris.data, iris.target
# 학습 데이터와 테스트 데이터로 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Extra Trees 모델 생성 및 학습
clf = ExtraTreesClassifier(n_estimators=100, max_depth=3, random_state=42)
clf.fit(X_train, y_train)
# 예측 및 평가
y_pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
# 중요 특징 시각화
feature_importances = clf.feature_importances_
features = iris.feature_names
importance_df = pd.DataFrame({'Feature': features, 'Importance': feature_importances})
plt.figure(figsize=(10, 6))
sns.barplot(x='Importance', y='Feature', data=importance_df)
plt.title('Feature Importance in Extra Trees')
plt.show()
코드 설명
- 데이터 로드 및 분할:
load_iris()함수를 사용하여 아이리스 데이터를 로드하고,train_test_split()을 통해 학습 데이터와 테스트 데이터로 분할합니다. - 모델 생성 및 학습:
ExtraTreesClassifier를 사용하여 Extra Trees 모델을 생성하고,fit()함수를 사용하여 학습시킵니다. 여기서는 100개의 트리와 최대 깊이 3을 설정했습니다. - 예측 및 평가: 학습된 모델로 테스트 데이터를 예측하고, 정확도를 계산합니다.
- 중요 특징 시각화:
feature_importances_속성을 사용하여 각 특징의 중요도를 계산하고,seaborn을 사용하여 바 그래프로 시각화합니다.
6. XGBoost (Extreme Gradient Boosting)
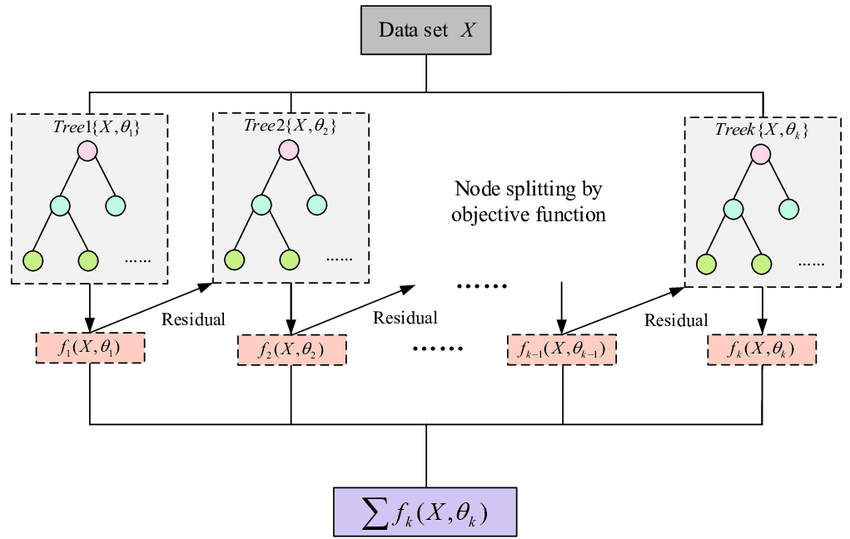
출처: ResearchGate, Flow chart of XGBoost
개념 및 원리
XGBoost (Extreme Gradient Boosting)는 그래디언트 부스팅 알고리즘을 확장하여 성능과 효율성을 크게 향상시킨 라이브러리입니다. XGBoost는 정규화, 병렬 처리, 조기 종료 등 여러 가지 최적화 기법을 사용하여 기존의 그래디언트 부스팅 알고리즘보다 뛰어난 성능을 제공합니다. 주요 개념은 다음과 같습니다:
- 정규화 (Regularization): L1, L2 정규화를 사용하여 모델의 복잡도를 제어하고 과적합을 방지합니다.
- 병렬 처리 (Parallel Processing): 다중 스레드를 사용하여 학습 속도를 향상시킵니다.
- 조기 종료 (Early Stopping): 검증 데이터의 성능 향상이 멈추면 학습을 조기 종료하여 과적합을 방지합니다.
- 분할 검색 최적화: 분할점을 효율적으로 찾기 위해 히스토그램 기반 접근법을 사용합니다.
파이썬 코드 예제
아래는 xgboost 라이브러리를 사용하여 XGBoost를 구현하는 예제입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
import xgboost as xgb
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
# 데이터 로드
iris = load_iris()
X, y = iris.data, iris.target
# 학습 데이터와 테스트 데이터로 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# XGBoost 모델 생성 및 학습
clf = xgb.XGBClassifier(n_estimators=100, learning_rate=0.1, max_depth=3, random_state=42, use_label_encoder=False)
clf.fit(X_train, y_train, eval_metric='logloss')
# 예측 및 평가
y_pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
# 중요 특징 시각화
feature_importances = clf.feature_importance()
features = iris.feature_names
importance_df = pd.DataFrame({'Feature': features, 'Importance': feature_importances})
plt.figure(figsize=(10, 6))
sns.barplot(x='Importance', y='Feature', data=importance_df)
plt.title('Feature Importance in XGBoost')
plt.show()
코드 설명
- 데이터 로드 및 분할:
load_iris()함수를 사용하여 아이리스 데이터를 로드하고,train_test_split()을 통해 학습 데이터와 테스트 데이터로 분할합니다. - 모델 생성 및 학습:
XGBClassifier를 사용하여 XGBoost 모델을 생성하고,fit()함수를 사용하여 학습시킵니다. 여기서는 100개의 트리, 학습률 0.1, 최대 깊이 3으로 설정했습니다.use_label_encoder=False는 최신 버전의 XGBoost에서 경고를 방지하기 위한 설정입니다. - 예측 및 평가: 학습된 모델로 테스트 데이터를 예측하고, 정확도를 계산합니다.
- 중요 특징 시각화:
feature_importance()함수를 사용하여 각 특징의 중요도를 계산하고,seaborn을 사용하여 바 그래프로 시각화합니다.
7. LightGBM (Light Gradient Boosting Machine)
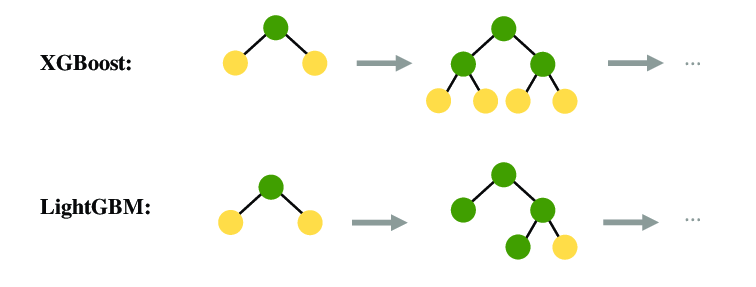
출처 : https://www.linkedin.com/pulse/xgboost-vs-lightgbm-ashik-kumar/
개념 및 원리
LightGBM (Light Gradient Boosting Machine)은 대용량 데이터와 고차원 데이터를 효율적으로 처리할 수 있도록 설계된 그래디언트 부스팅 프레임워크입니다. LightGBM은 리프 중심 트리 분할 방식과 여러 최적화 기법을 사용하여 학습 속도를 크게 향상시킵니다. 주요 개념은 다음과 같습니다:
- 리프 중심 트리 분할 (Leaf-wise Tree Growth): 트리의 리프를 확장하는 방식으로, 손실을 가장 많이 줄이는 리프를 선택하여 분할합니다. 이는 깊이 중심 분할보다 더 효과적입니다.
- Gradient-based One-Side Sampling (GOSS): 중요한 샘플을 더 많이 사용하고 덜 중요한 샘플을 줄여 데이터의 크기를 줄입니다.
- Exclusive Feature Bundling (EFB): 상호 배타적인 특징을 하나로 묶어 특징의 수를 줄입니다.
- Histogram-based Decision Tree: 연속형 특징을 히스토그램으로 변환하여 빠른 분할점을 찾습니다.
파이썬 코드 예제
아래는 lightgbm 라이브러리를 사용하여 LightGBM을 구현하는 예제입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
import lightgbm as lgb
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
# 데이터 로드
iris = load_iris()
X, y = iris.data, iris.target
# 학습 데이터와 테스트 데이터로 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# LightGBM 데이터셋 생성
train_data = lgb.Dataset(X_train, label=y_train)
test_data = lgb.Dataset(X_test, label=y_test, reference=train_data)
# LightGBM 모델 파라미터 설정
params = {
'boosting_type': 'gbdt',
'objective': 'multiclass',
'num_class': 3,
'metric': 'multi_logloss',
'learning_rate': 0.1,
'max_depth': 3,
'num_leaves': 31,
'random_state': 42
}
# 모델 학습
clf = lgb.train(params, train_data, num_boost_round=100, valid_sets=[test_data], early_stopping_rounds=10)
# 예측 및 평가
y_pred = clf.predict(X_test, num_iteration=clf.best_iteration)
y_pred = [np.argmax(line) for line in y_pred]
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
# 중요 특징 시각화
feature_importances = clf.feature_importance()
features = iris.feature_names
importance_df = pd.DataFrame({'Feature': features, 'Importance': feature_importances})
plt.figure(figsize=(10, 6))
sns.barplot(x='Importance', y='Feature', data=importance_df)
plt.title('Feature Importance in LightGBM')
plt.show()
코드 설명
- 데이터 로드 및 분할:
load_iris()함수를 사용하여 아이리스 데이터를 로드하고,train_test_split()을 통해 학습 데이터와 테스트 데이터로 분할합니다. - LightGBM 데이터셋 생성:
lgb.Dataset를 사용하여 LightGBM의 데이터셋 형식으로 변환합니다. - 모델 파라미터 설정:
params딕셔너리를 사용하여 모델의 파라미터를 설정합니다. 여기서는 다중 클래스 분류를 위한 파라미터를 설정합니다. - 모델 학습:
lgb.train()함수를 사용하여 모델을 학습시킵니다.early_stopping_rounds를 설정하여 검증 데이터의 성능 향상이 멈추면 학습을 조기 종료합니다. - 예측 및 평가: 학습된 모델로 테스트 데이터를 예측하고, 정확도를 계산합니다.
- 중요 특징 시각화:
feature_importance()함수를 사용하여 각 특징의 중요도를 계산하고,seaborn을 사용하여 바 그래프로 시각화합니다.
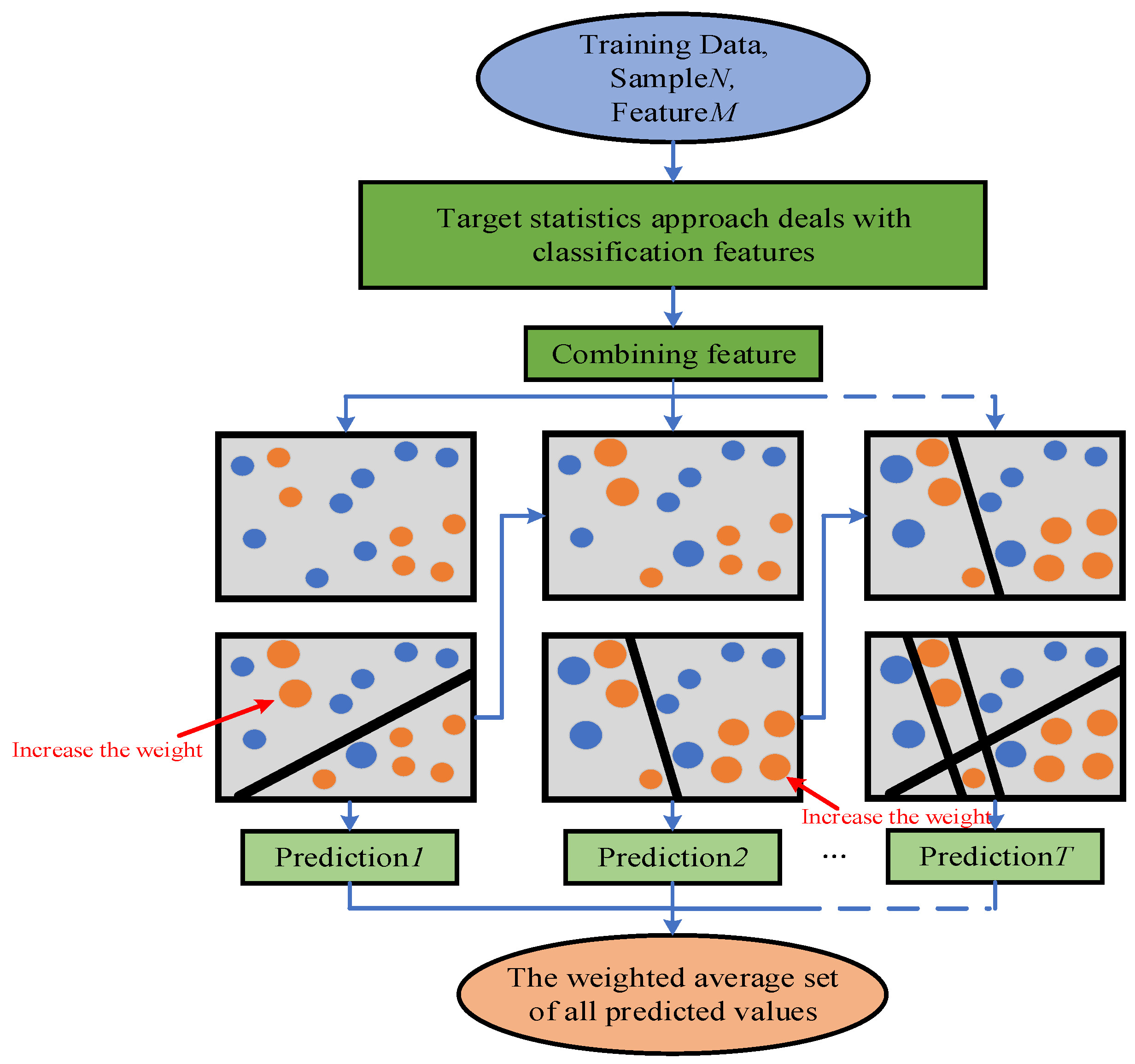
8. CatBoost (Categorical Boosting)
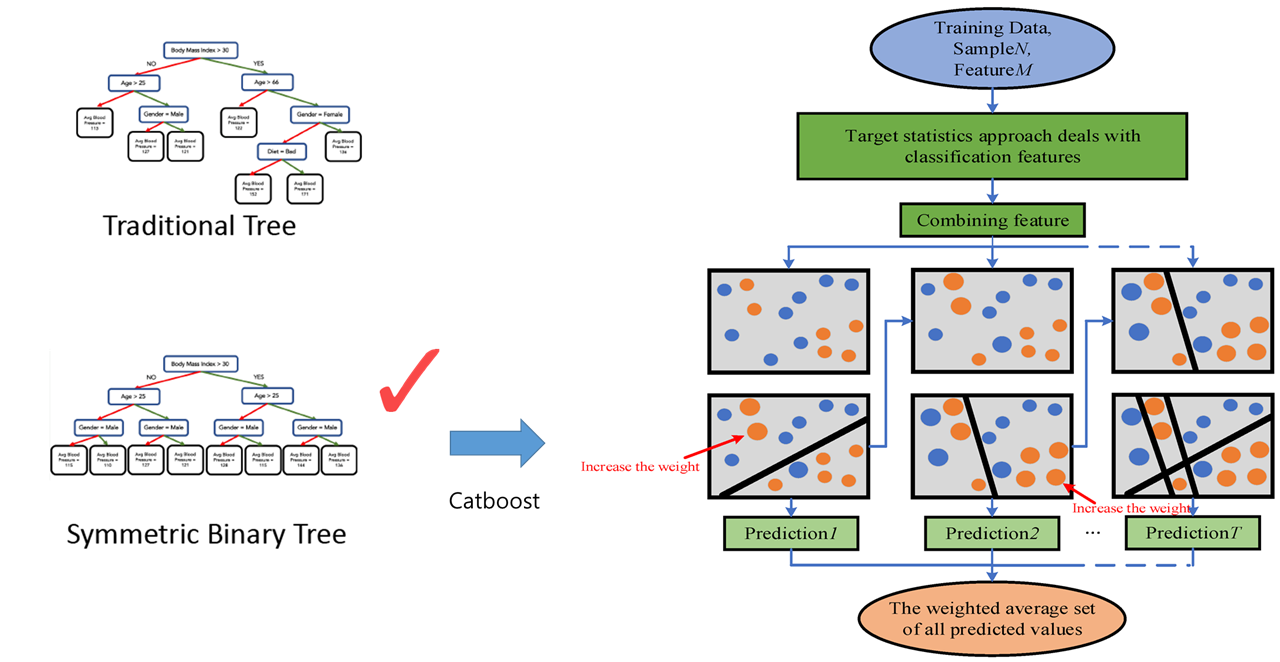
출처 : https://www.mdpi.com/sensors/sensors-23-01811/article_deploy/html/images/sensors-23-01811-g003.png
{kind=link}
개념 및 원리
CatBoost (Categorical Boosting)는 범주형 변수를 효과적으로 처리할 수 있도록 설계된 그래디언트 부스팅 프레임워크입니다. CatBoost는 범주형 변수의 고유한 처리 방법과 순차 부스팅 기법을 통해 예측 성능과 학습 속도를 향상시킵니다. 주요 개념은 다음과 같습니다:
- 순차 부스팅 (Ordered Boosting): 데이터 순서를 무작위로 섞어 부스팅 단계마다 새로운 순서를 사용하여 과적합을 방지합니다.
- 범주형 변수 처리: 각 범주형 변수에 대해 고유한 통계량(평균 목표값 등)을 사용하여 변환합니다.
- 대칭 트리 (Symmetric Trees): 균형 잡힌 트리 구조를 사용하여 예측 속도를 높이고, 메모리 사용을 최적화합니다.
- 기타 최적화: GPU 지원, 조기 종료, 정규화 등의 다양한 최적화 기법을 포함합니다.
파이썬 코드 예제
아래는 catboost 라이브러리를 사용하여 CatBoost를 구현하는 예제입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
import catboost as cb
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
# 데이터 로드
iris = load_iris()
X, y = iris.data, iris.target
# 학습 데이터와 테스트 데이터로 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# CatBoost 모델 생성 및 학습
clf = cb.CatBoostClassifier(iterations=100, learning_rate=0.1, depth=3, random_seed=42, verbose=0)
clf.fit(X_train, y_train)
# 예측 및 평가
y_pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
# 중요 특징 시각화
feature_importances = clf.get_feature_importance()
features = iris.feature_names
importance_df = pd.DataFrame({'Feature': features, 'Importance': feature_importances})
plt.figure(figsize=(10, 6))
sns.barplot(x='Importance', y='Feature', data=importance_df)
plt.title
('Feature Importance in CatBoost')
plt.show()
코드 설명
- 데이터 로드 및 분할:
load_iris()함수를 사용하여 아이리스 데이터를 로드하고,train_test_split()을 통해 학습 데이터와 테스트 데이터로 분할합니다. - 모델 생성 및 학습:
CatBoostClassifier를 사용하여 CatBoost 모델을 생성하고,fit()함수를 사용하여 학습시킵니다. 여기서는 100번의 반복(iterations), 학습률 0.1, 최대 깊이 3을 설정했습니다. - 예측 및 평가: 학습된 모델로 테스트 데이터를 예측하고, 정확도를 계산합니다.
- 중요 특징 시각화:
get_feature_importance()함수를 사용하여 각 특징의 중요도를 계산하고,seaborn을 사용하여 바 그래프로 시각화합니다.
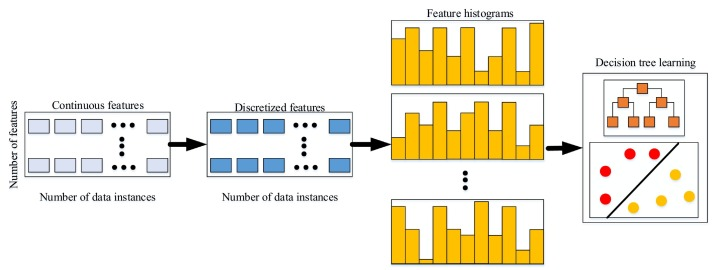
9. Histogram-based Gradient Boosting (HGBT)
출처 : https://ars.els-cdn.com/content/image/1-s2.0-S0926580523000274-gr3.jpg
{kind=link}
개념 및 원리
히스토그램 기반 그래디언트 부스팅은 히스토그램을 사용하여 연속형 특징을 버킷으로 그룹화하여 분할점을 찾는 효율적인 방법입니다. 이 접근법은 계산 속도를 크게 향상시키고 메모리 사용량을 줄이며, 대용량 데이터셋을 처리하는 데 유리합니다. 주요 개념은 다음과 같습니다:
- 히스토그램 변환: 연속형 특징을 일정한 간격 또는 데이터 분포에 따라 버킷으로 변환합니다.
- 빠른 분할점 찾기: 각 버킷 내에서 손실 함수를 최소화하는 분할점을 빠르게 찾습니다.
- 대용량 데이터 처리: 히스토그램 기반 접근법은 병렬 처리를 통해 대용량 데이터셋에서도 높은 효율성을 제공합니다.
파이썬 코드 예제
아래는 scikit-learn의 HistGradientBoostingClassifier를 사용하여 히스토그램 기반 그래디언트 부스팅을 구현하는 예제입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
from sklearn.experimental import enable_hist_gradient_boosting
from sklearn.ensemble import HistGradientBoostingClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
# 데이터 로드
iris = load_iris()
X, y = iris.data, iris.target
# 학습 데이터와 테스트 데이터로 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 히스토그램 기반 그래디언트 부스팅 모델 생성 및 학습
clf = HistGradientBoostingClassifier(max_iter=100, learning_rate=0.1, max_depth=3, random_state=42)
clf.fit(X_train, y_train)
# 예측 및 평가
y_pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
# 중요 특징 시각화
feature_importances = clf.feature_importances_
features = iris.feature_names
importance_df = pd.DataFrame({'Feature': features, 'Importance': feature_importances})
plt.figure(figsize=(10, 6))
sns.barplot(x='Importance', y='Feature', data=importance_df)
plt.title('Feature Importance in Histogram-based Gradient Boosting')
plt.show()
코드 설명
- 데이터 로드 및 분할:
load_iris()함수를 사용하여 아이리스 데이터를 로드하고,train_test_split()을 통해 학습 데이터와 테스트 데이터로 분할합니다. - 모델 생성 및 학습:
HistGradientBoostingClassifier를 사용하여 히스토그램 기반 그래디언트 부스팅 모델을 생성하고,fit()함수를 사용하여 학습시킵니다. 여기서는 100번의 반복(iterations), 학습률 0.1, 최대 깊이 3을 설정했습니다. - 예측 및 평가: 학습된 모델로 테스트 데이터를 예측하고, 정확도를 계산합니다.
- 중요 특징 시각화:
feature_importances_속성을 사용하여 각 특징의 중요도를 계산하고,seaborn을 사용하여 바 그래프로 시각화합니다.
10. 정리
다음은 scikit-learn을 사용하여 여러 트리 기반 알고리즘을 학습하고 검증 성능을 비교하는 코드입니다. 이 코드는 아이리스 데이터를 사용하여 각 알고리즘의 성능을 데이터프레임 형태로 저장합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier, AdaBoostClassifier, ExtraTreesClassifier, HistGradientBoostingClassifier
import xgboost as xgb
import lightgbm as lgb
import catboost as cb
import pandas as pd
# 데이터 로드 및 분할
iris = load_iris()
X, y = iris.data, iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 알고리즘 리스트
classifiers = {
"Decision Tree": DecisionTreeClassifier(max_depth=3, random_state=42),
"Random Forest": RandomForestClassifier(n_estimators=100, max_depth=3, random_state=42),
"Gradient Boosting": GradientBoostingClassifier(n_estimators=100, learning_rate=0.1, max_depth=3, random_state=42),
"AdaBoost": AdaBoostClassifier(estimator=DecisionTreeClassifier(max_depth=1, random_state=42), n_estimators=50, learning_rate=1.0, random_state=42),
"Extra Trees": ExtraTreesClassifier(n_estimators=100, max_depth=3, random_state=42),
"XGBoost": xgb.XGBClassifier(n_estimators=100, learning_rate=0.1, max_depth=3, random_state=42, use_label_encoder=False, eval_metric='logloss'),
"LightGBM": lgb.LGBMClassifier(n_estimators=100, learning_rate=0.1, max_depth=3, random_state=42),
"CatBoost": cb.CatBoostClassifier(iterations=100, learning_rate=0.1, depth=3, random_seed=42, verbose=0),
"HistGradientBoosting": HistGradientBoostingClassifier(max_iter=100, learning_rate=0.1, max_depth=3, random_state=42)
}
# 성능 저장을 위한 리스트
results = []
# 알고리즘별 성능 평가
for name, clf in classifiers.items():
clf.fit(X_train, y_train)
train_accuracy = clf.score(X_train, y_train)
test_accuracy = clf.score(X_test, y_test)
cross_val_scores = cross_val_score(clf, X, y, cv=5)
cross_val_mean = cross_val_scores.mean()
cross_val_std = cross_val_scores.std()
results.append({
"Algorithm": name,
"Train Accuracy": train_accuracy,
"Test Accuracy": test_accuracy,
"Cross-Validation Mean": cross_val_mean,
"Cross-Validation Std": cross_val_std
})
# 리스트를 데이터프레임으로 변환
results_df = pd.DataFrame(results)
# 결과 출력
print(results_df)
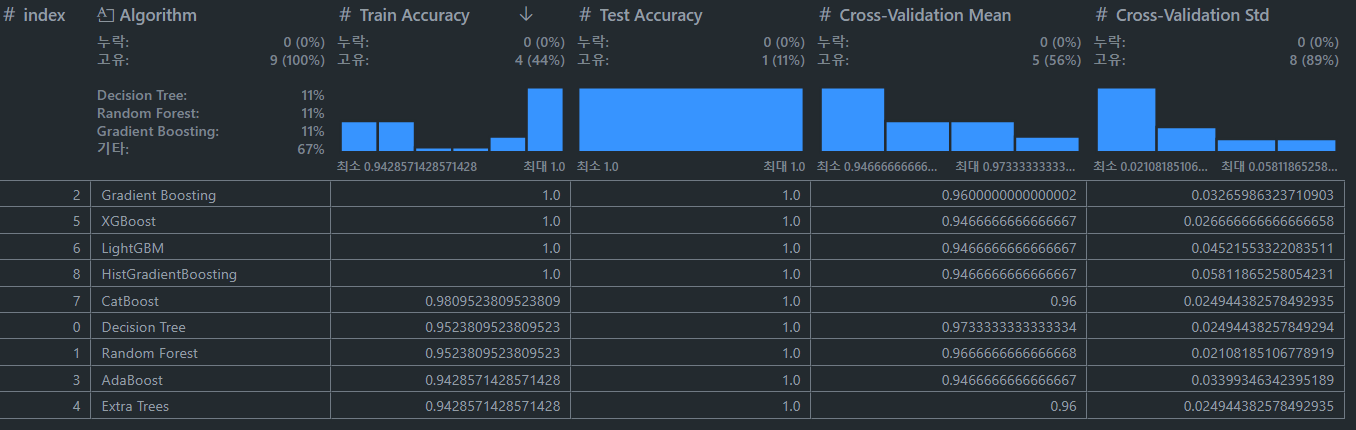
오늘은 트리 기반 ML 알고리즘 전반에 대해서 정리하고, 기본적인 코드까지 적어보는 시간을 가져봤는데요 📊 저도 개인적으로 한번쯤 정리하고 가고 싶었던 개념이라 유익했던 시간이었던 것 같습니다!!
감사합니다 🙏